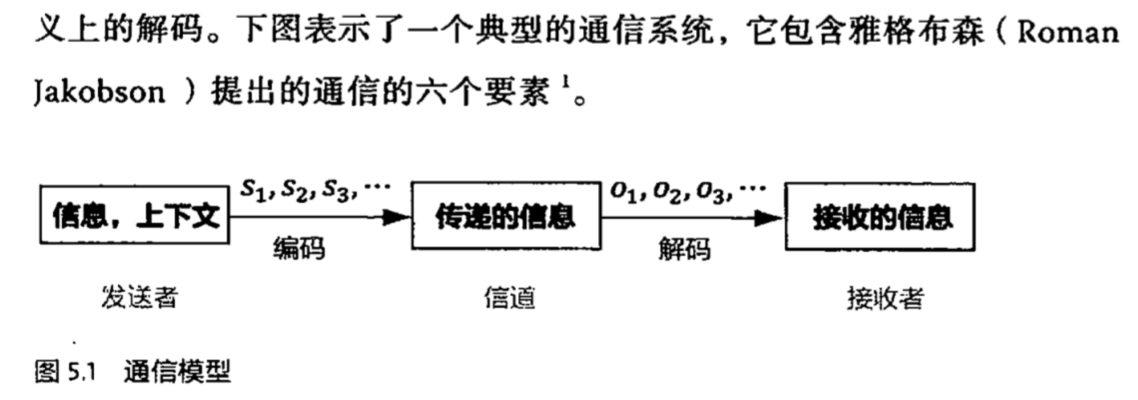
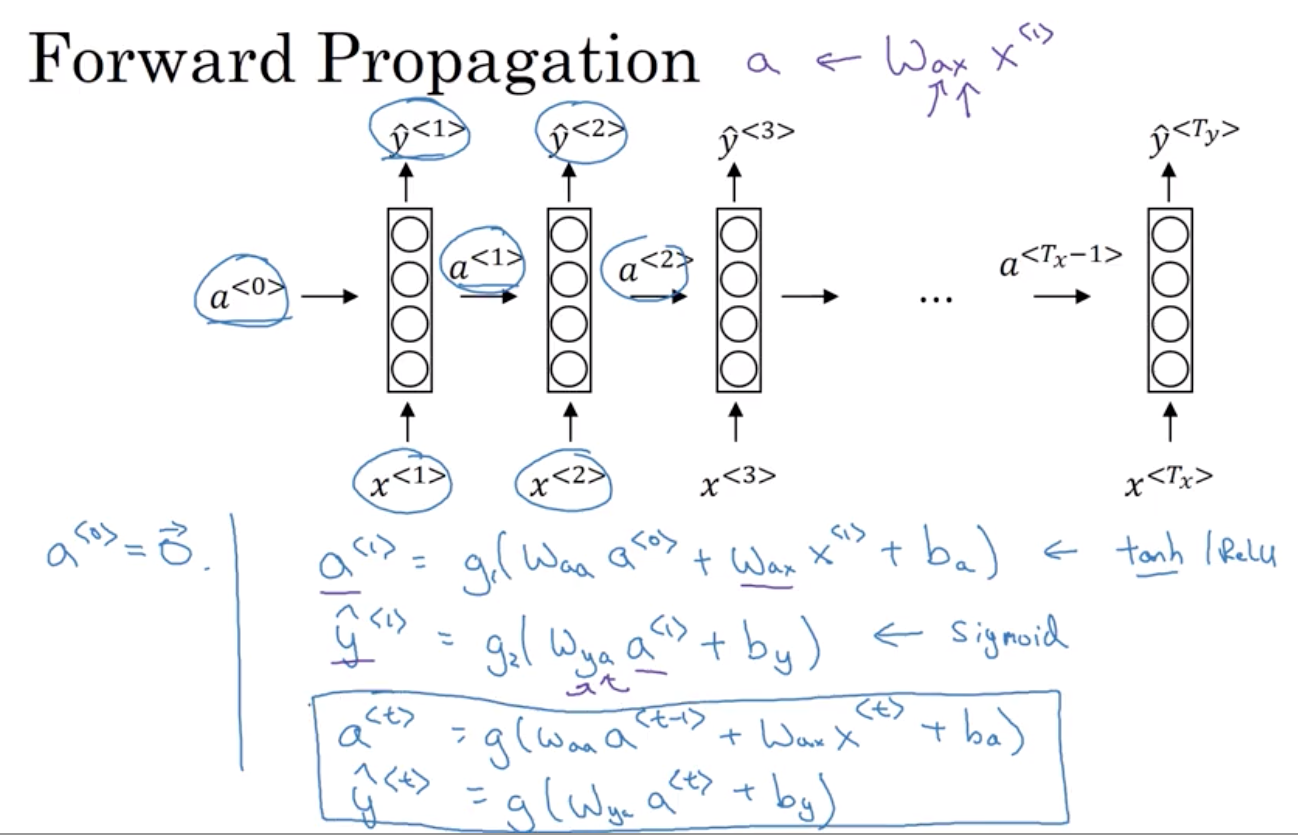
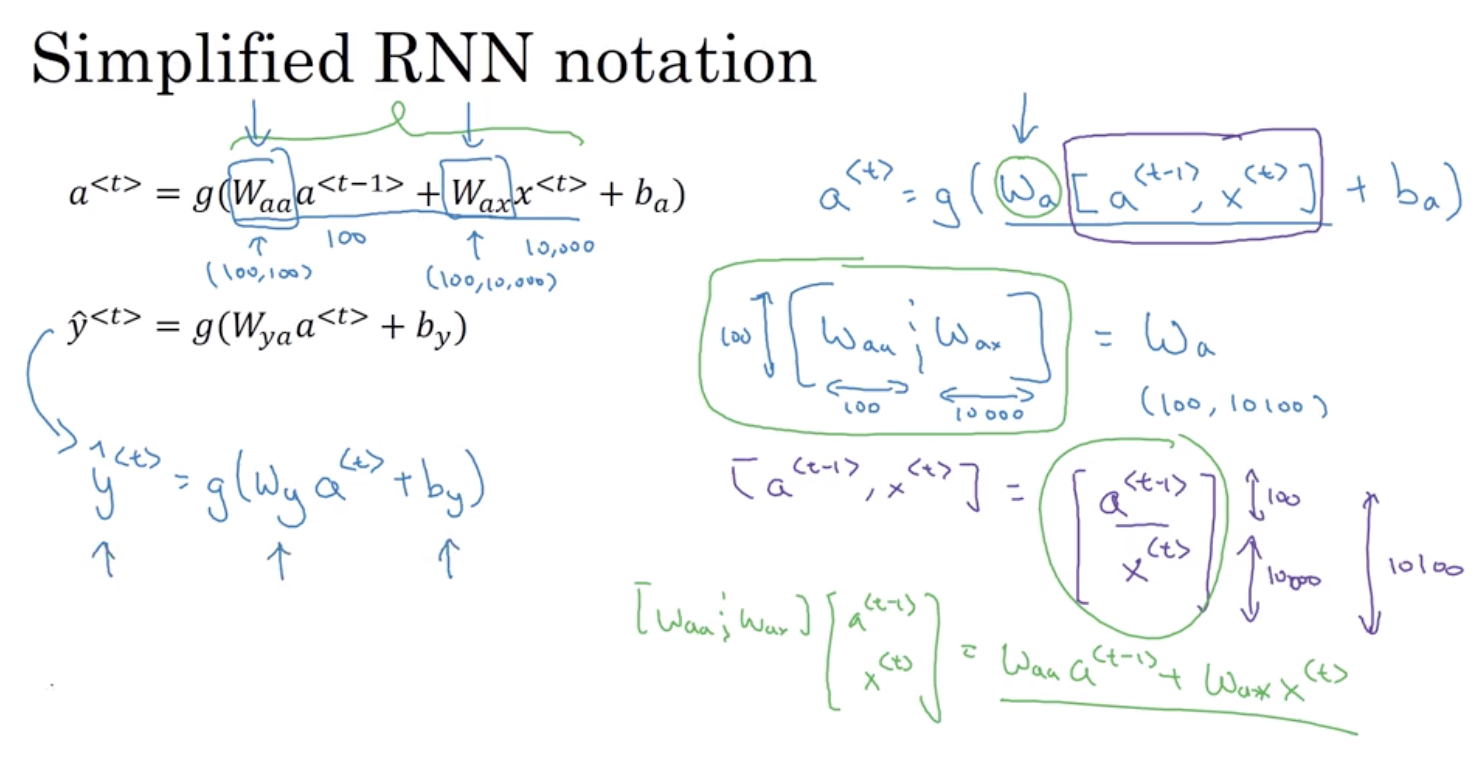
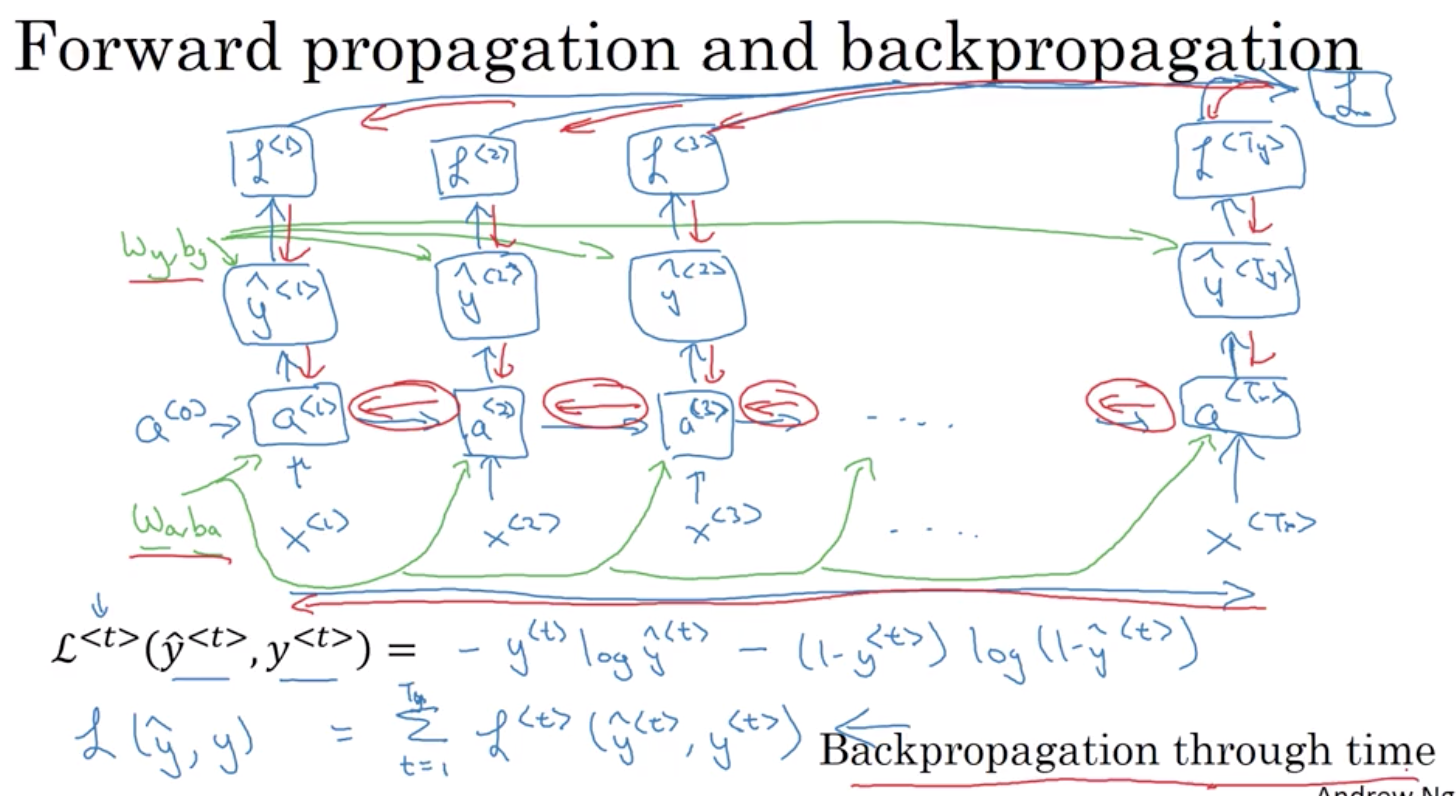
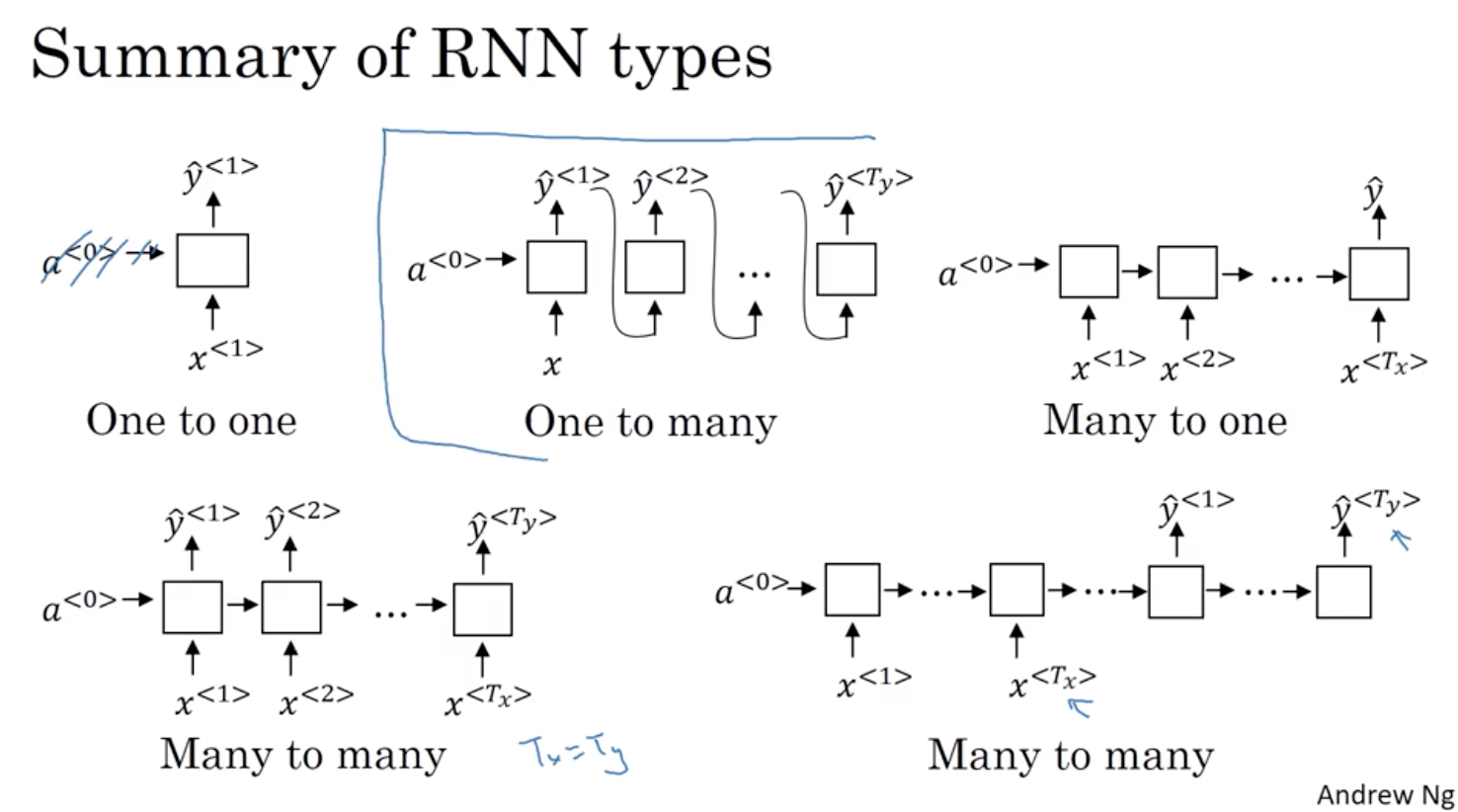
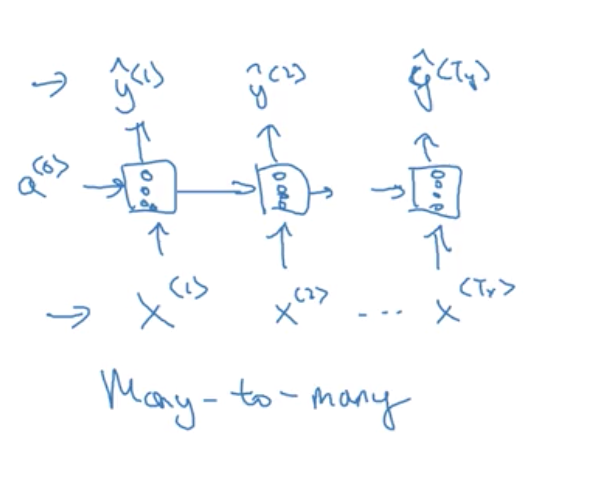
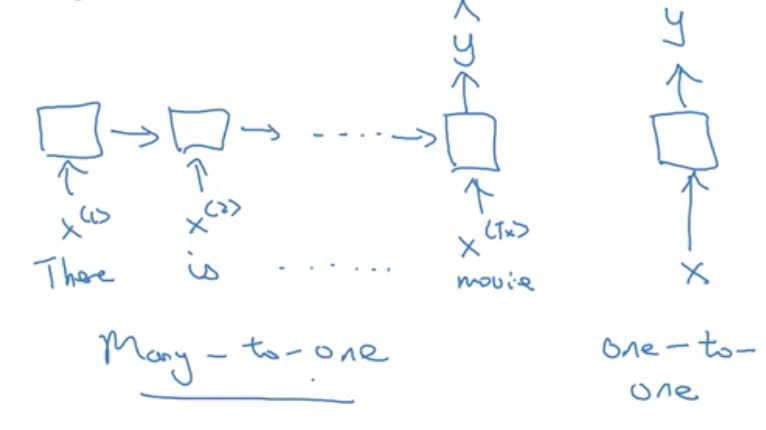
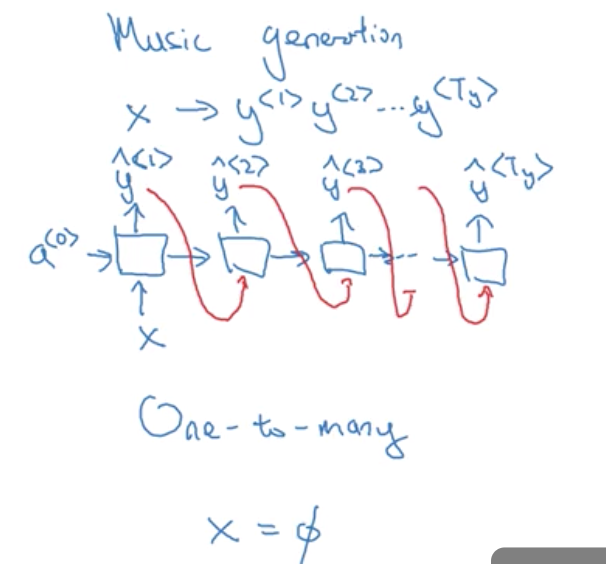
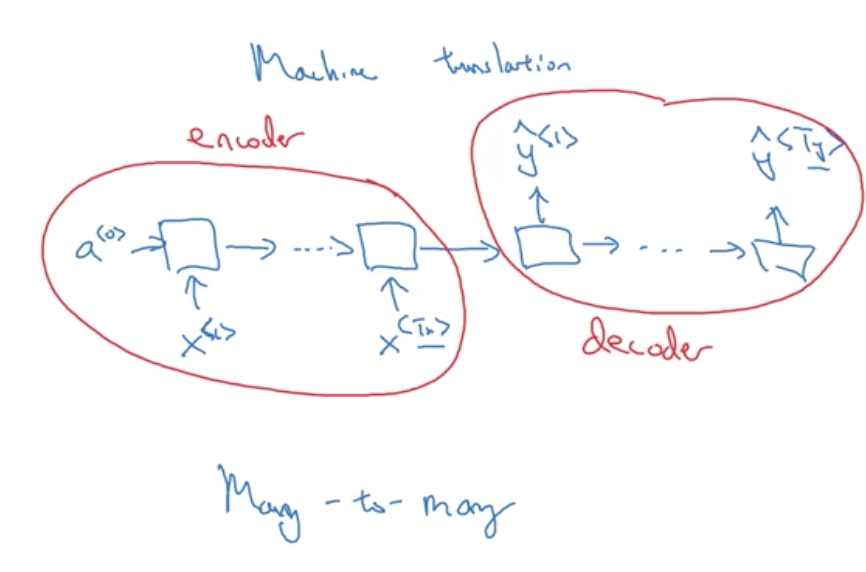
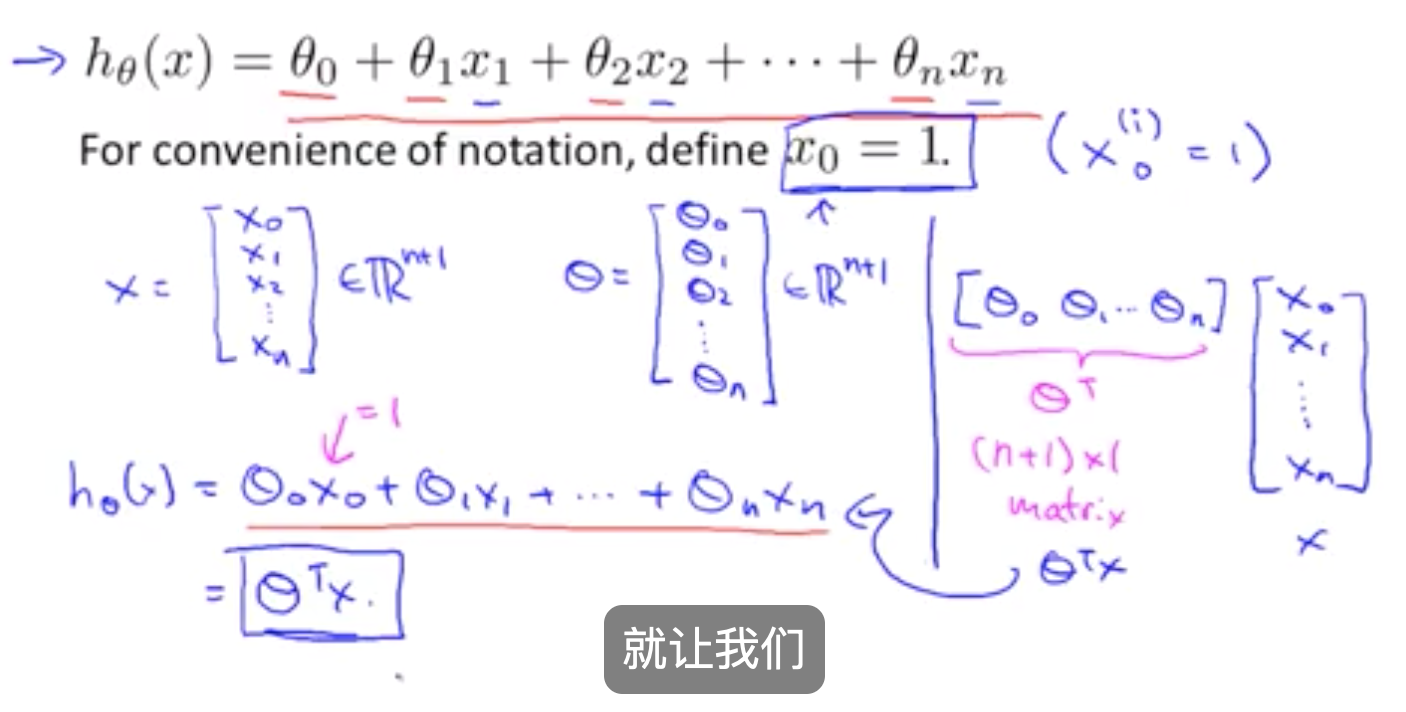
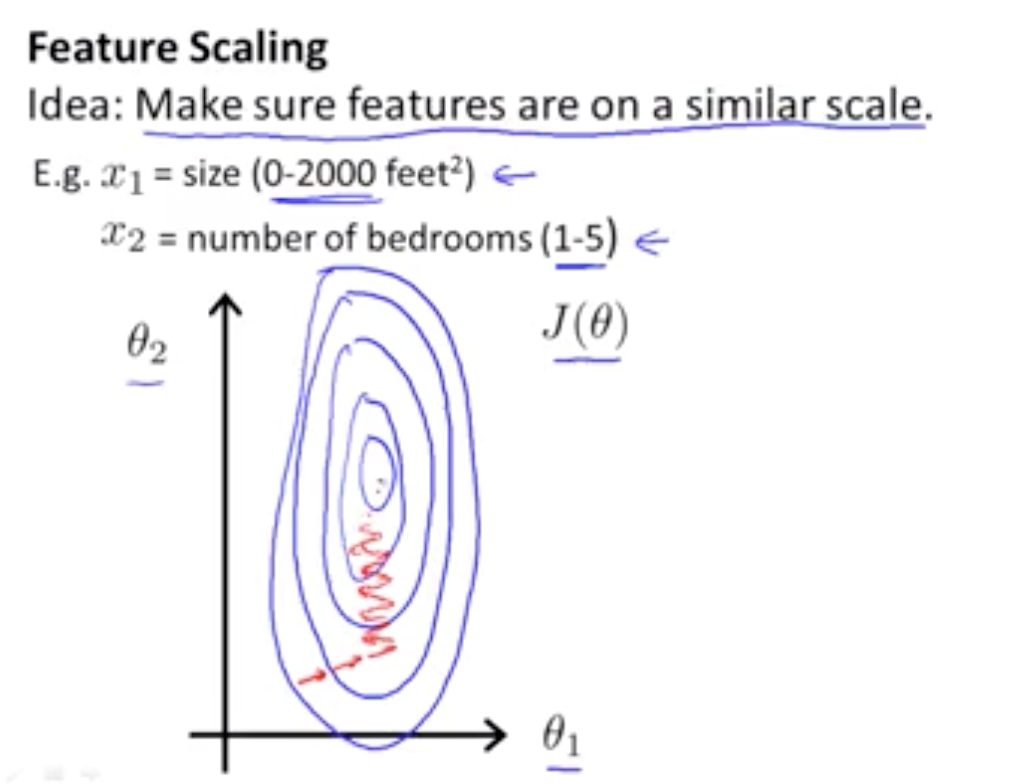
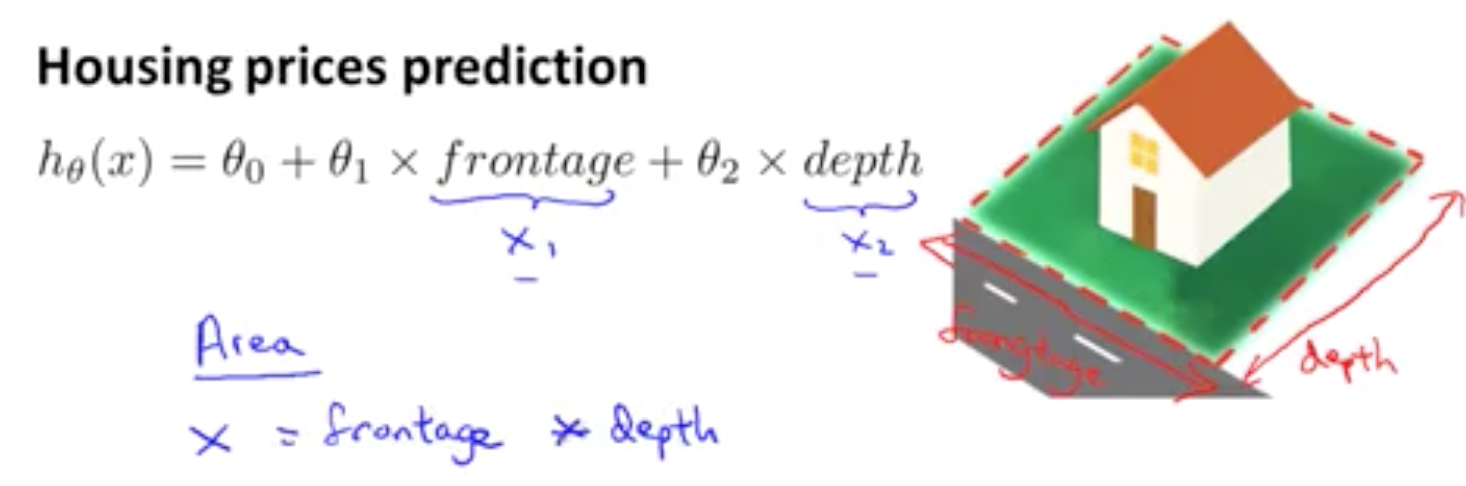
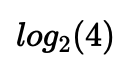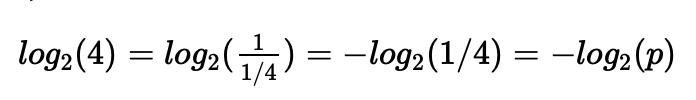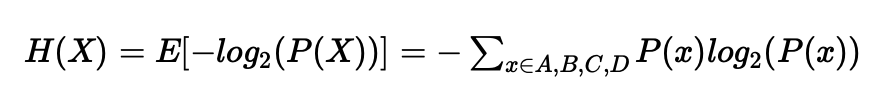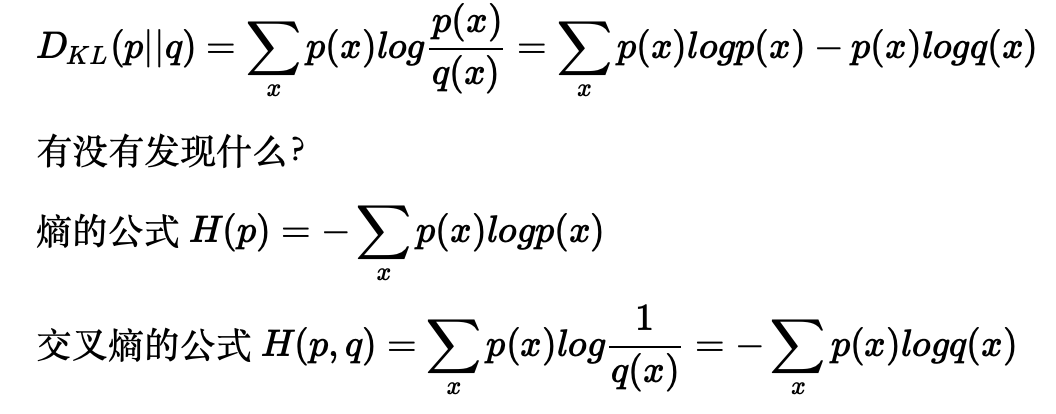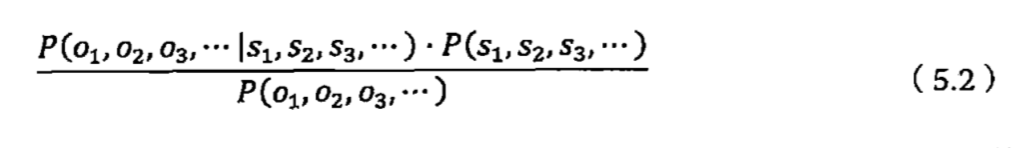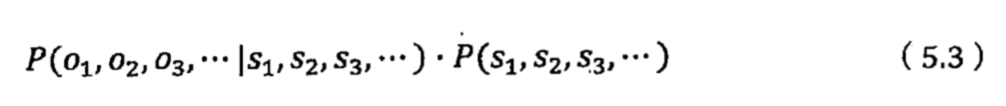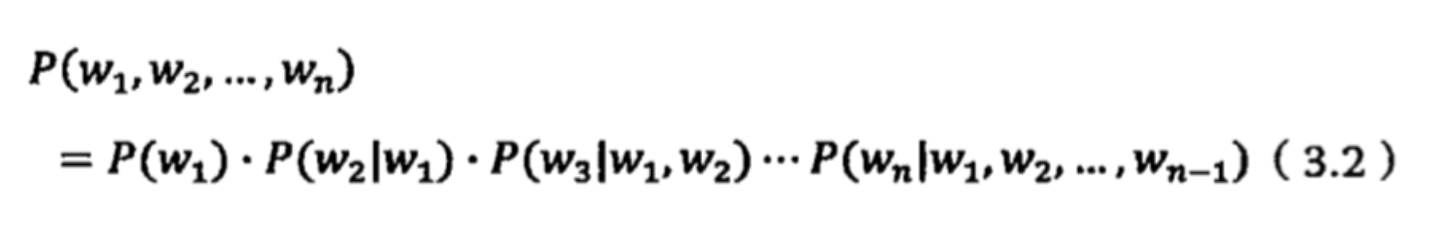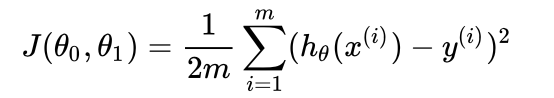Welcome to MyBlog! This article was writed to take note my study of Machine Learning on Cousera.
1 机器学习策略
1.1 什么是机器学习策略?
有快捷高效的方法 分辨出在之前提到的或者没有提到的各种想法中 哪些值得进行尝试 哪些可以直接放弃
一些基本套路 也就是一些分析机器学习问题的方法 这些方法 会让你避免南辕北辙
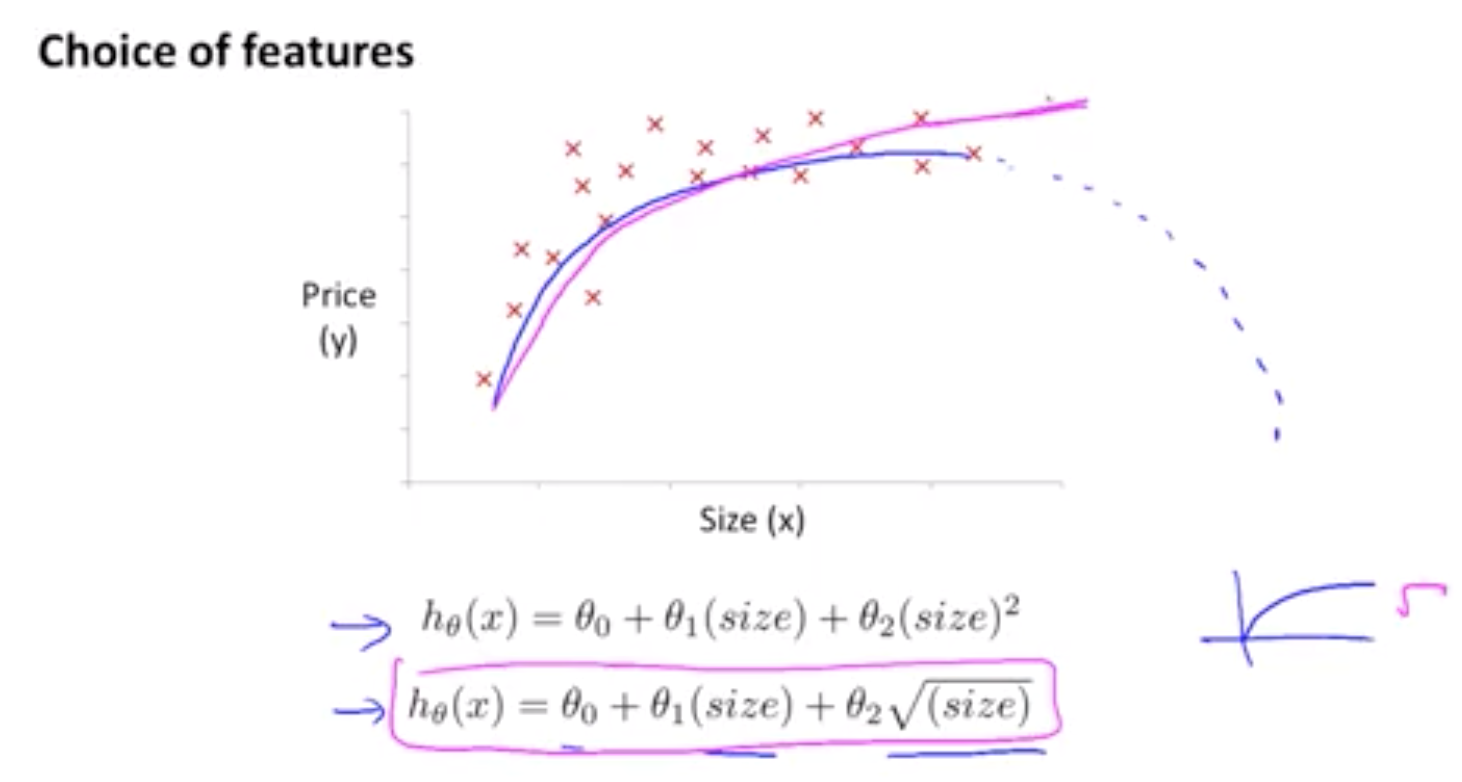
1.2 正交化过程(调参,参数之间互不干扰)
建立机器学习系统的挑战之一是*有太多可以尝试和改变的东西**,例如调整的超参数。
最高效的机器学习人员都非常清楚需要调整什么,我们称这一过程为正交化***。
实例:
正交化就是指电视设计师 So in this context, orthogonalization refers to that
the TV designers 在进行设计的时候 确保每个旋钮只能进行一个参数的调整 had designed
the knobs so that each knob kind of does only one thing
而这让电视屏幕的调整变得更加容易 And this makes it much easier to tune the TV,
so 使得电视画面能够显示在你希望的位置上 that the picture gets centered where you
want it to be.
为保证有监督脊椎的学习系统良好地运行,调整系统旋钮,保证四件事准确无误。
(1)通常确保至少训练组运行良好。因此训练组的运行情况需要进行一些可行性评估。
如果训练组表现良好, 你将希望这能使开发组运行良好,同时 你也会希望测试组运行良好, 最终 你希望能在成本函数的测试组里运行良好,因为结果会影响系统在实际情况中的表现, 因此 希望这能顺利地实现,
(2)相反,如果你发现算法对dev集的拟合结果不太好 那么 就需要另一套独立的旋钮 是的,这就是我画的不太好的,另一套旋钮 你需要有一套不同的旋钮 来调整(开发集的拟合结果)
(3)如果(算法)在dev集上表现很好 但是在测试集上不行呢? 如果这样, 你可能想要一个调整的旋钮 用来获取一个更大的dev集 因为如果(算法)在dev集上表现很好 但测试集上不行,这可能意味着, 你过度调节了dev集 你需要返回去,寻找一个更大的dev集
(4)如果(算法)在测试集上表现也很好 但是依然不能给你 愉快的用户体验,这意味着你需要返回去 调整你的dev集或者成本函数

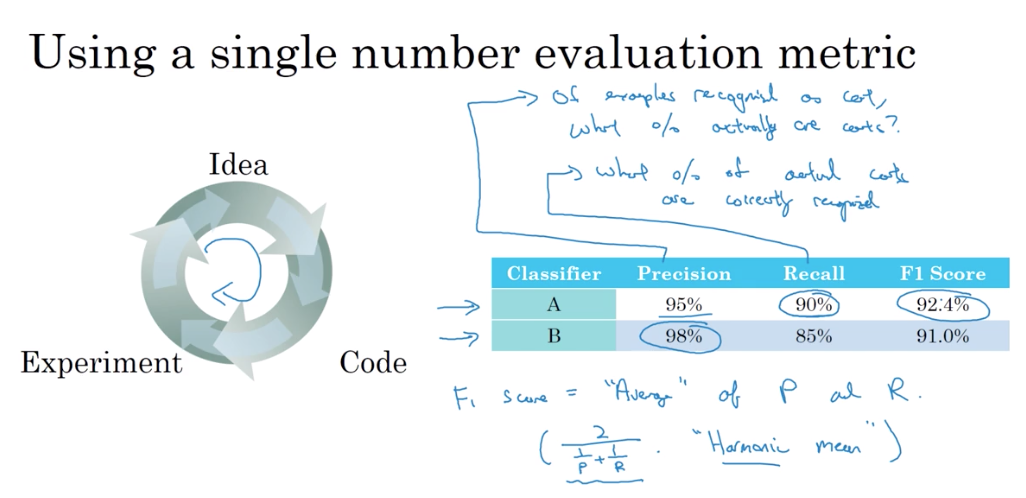
2. 单数评价指标
2.1 F1 score
因此分类器A有95%的精准率 就意味着 A如果把一张图片分类为猫 那么95%可能它就是猫
而召回率就是 对于所有是猫的图片 你的分类器有多少百分比可以正确的识别出来
即多少比率的真猫被正确的识别出了
2.2 满足指标(satisficing matrics)和 优化指标(optimizing matrics)
如果你同时关心多项指标, 你可以将其中的一样设为优化指标, 使其表现尽可能的好 ,将另外的一项或多项设为满足指标,确保其表现满足要求,大多数情况下他们都会优于最低标准,这样一来你就有了一个几乎自动的, 快速评价模型和选择”最佳”模型的方法
例子:
你决定关注 猫分类器的分类准确率(accuracy) 它可以是F1分数(F1 score)
或者别的什么精确度度量 但是假设 除了准确率之外你还关心运行时间
也就是对一个图像分类需要多少时间
这个表中分类器A需要80毫秒(millisecond)
B需要95毫秒 C需要1,500毫秒 也就是1.5秒才能甄别一个图像
你当然可以将准确率和运行时间组合成一个 整体评价指标(overall evaluation metric)
比如说整体代价是 准确率-0.5*运行时间 但是将准确率和运行时间用这样的公式整合
看起来有些刻意 这就像二者的线性加权和(linear weighted sum) 所以你还可以这样做:
你可能想要选择一个分类器 它在确保运行时间的前提下提供最大准确率
比如说它甄别图像所花费的时间 必须<=100毫秒 在这个例子中我们说准确率是优化指标
因为你想要最大化准确率 你希望准确率尽可能的高 但是运行时间是我们我们所说的满足指标
意味着它必须足够好 必须<100毫秒 一旦超出即不予考虑 至少不大考虑
所以用这种方式对准确率和运行时间

3. train/dev/test
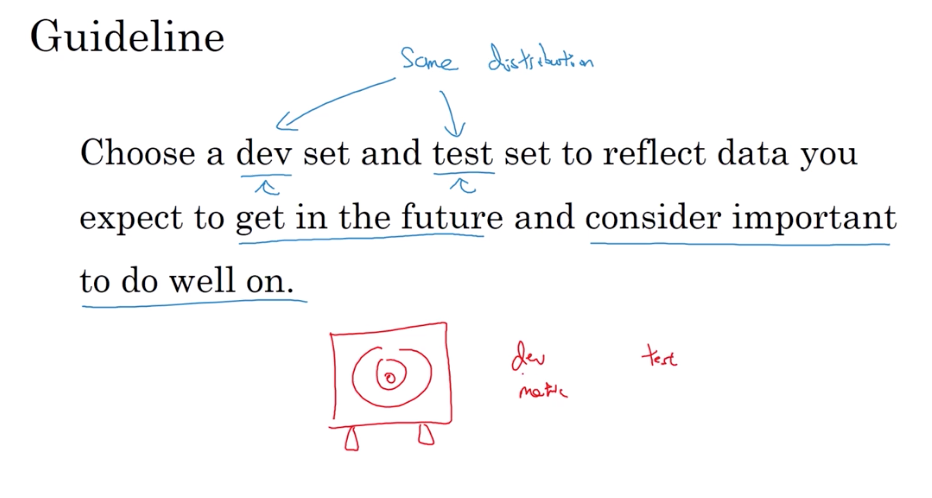
3.1 开发集(dev)和测试集 应具有相同的分布
dev set 也被称为development set 或者有些时候被称为交叉验证集
机器学习的工作流程是 你尝试了很多想法, 在训练集上训练不同的模型, 然后使用开发集来 评估不同的想法,并选择一个。 并且,保持创新, 提高模型在开发集上的表现性能 直到最后你有一个很高兴的结果 然后你在测试集上评估它们
设置开发集 和检验方法 直接决定了你的目标 将开发和测试集取在同一分布上 你才真正瞄准了你和你团队的目标 你选择训练集的方法 会影响你击中目标的精度
3.2 训练集、开发集、测试集的数据分布
该内容在之前的博客上已经记录过,在此不再赘述,blog
3.3 改变 开发集/测试集 和 评估标准
我们已经学习了如何设置开发集和评估指标 这就好比确定你的团队要瞄准的靶子 可有时候 项目进行到一半 你可能会发现 靶子放错了位置 这时候 就应该移动你的靶子
当你发现评估指标 无法对算法的优劣给出正确的排序时 那么就需要考虑定义一个新的评估指标 这里的例子只是定义评估指标的一种方法 评价指标的目的是为了能够准确地告诉你 给出两个分类器 哪一个更适合你的应用 就本次视频的目标而言 大家不需要太关心如何定义新的误差指标 重点是 如果你对原有的误差指标不满意 那就不要将就着使用这个你不满意的指标 而是定义一个新的指标 使其能够更好地 反应你的偏好 以符合你对更好的算法的定义
3.4 定义评估指标十分重要

4. 和人类级别绩效 比较
4.1 为什么和人类级别绩效比较
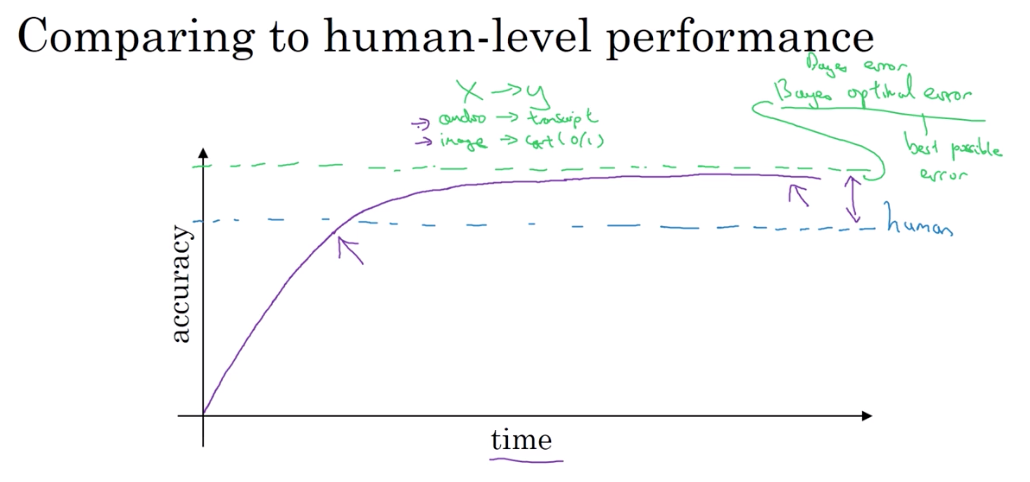
当你继续训练算法时 也许是越来越大模型和更多更大的数据 其效果逼近但从来不会超越一个理论值 这称为贝叶斯最优误差 所以贝叶斯最优误差就是最小的理论误差值
举例:
这就是用 从x到y的任何函数映射超过一定的准确度
例如对于语音识别,如果x是音频,一些音频就是 太多吵噪而无法判断它在讲什么
所以理论准确度可能不是 100% 或是猫识别 一些图像很模糊,它是不可能让
任何人或其他什么事物认出那幅画里有一只猫 所以,精度的完美水平可能不是100%
贝叶斯最优误差,贝叶斯最佳误差或贝叶斯错误 简而言之,是从x到y映射的最好的理论函数
事实证明,进度往往相当快 直到你超越人类的表现
你若超越了人类的表现,有时反而慢下来 我认为有两个主要原因 为什么当你超越人类级别的表现时进展往往放慢 原因之一,人类级别的表现 在许多任务中都离贝叶斯最优误差不远 人非常擅长看着图像去分辨是否有一只猫 或收听音频并写出字幕。 因此,可能算法超越人类级别的表现之后并没有,那么大的改善空间
第二个原因,只要你的表现还不如人类水平 那么实际上你可以用某些工具来提高 而当你超越了人类的水平后,就很难再有工具来提高了 就是这样子
只要你的机器学习算法 比人类更糟糕,你就可以从人类得到数据标记 这是你可以问人,问聪明的人,为你的例子标签 这样你可以有更多的数据以满足你的学习算法 我们下周会讲的是手动误差分析 只要人类仍表现优于任何算法,你可以 让人看看你的算法算错的例子,然后了解 为什么人可以做到,但该算法却搞错了。你也可以得到更好的偏见分析和 方差,一旦你的算法做的比人类优异 这三招将变的很难应用

4.2 可避免误差(avoidable bias)
贝叶斯误差和训练集上的误差 之间的 距离,称为可避免的偏差。
模型在训练集与开发集上的误差之差 则是对模型中存在的方差问题的度量
把人类误差当做贝叶斯误差的替代值或估计值
有一个好的贝叶斯误差估计 可以很好的帮助你评估可避免的偏差和方差
从而更利于做决定究竟是专注于偏差降低技术 还是方差降低技术
这个方法在你超越人类水平表现之前是一直有效果的
不管你使用普通医生的还是 一个专业医生的或者是一个有经验的医生团队的 因为这里是4%或4.5% 这明显要大于方差误差(1%) 你必须要确保终止循环的条件一定会达成 你需要专注与降低偏差的技术比如训练更大网络 在让我们看第二个例子 比如你的训练误差是1%而你的验证误差是5% 出学术目的外 无论你选择1% 0.7%或是0.5%哪个 作为人类水平的表现都没有什么区别 因为不管你用哪个定义 你可避免误差的度量 我猜差不多是0%到0.5% 对不对? 这是人类水平的表现和你训练误差的差距 而这里的差距是4% 因此4%在这里要远大于可以避免的偏差 所以你需要专注于方差降低的技术 比如正则化或者使用一个更大的训练集 但是真正有问题的时候是如果你的训练集误差为0.7% 当然这已经非常好了 而你的开发集误差为0.8% 在这种情况下把你的贝叶斯误差估计定为0.5%就很有必要了

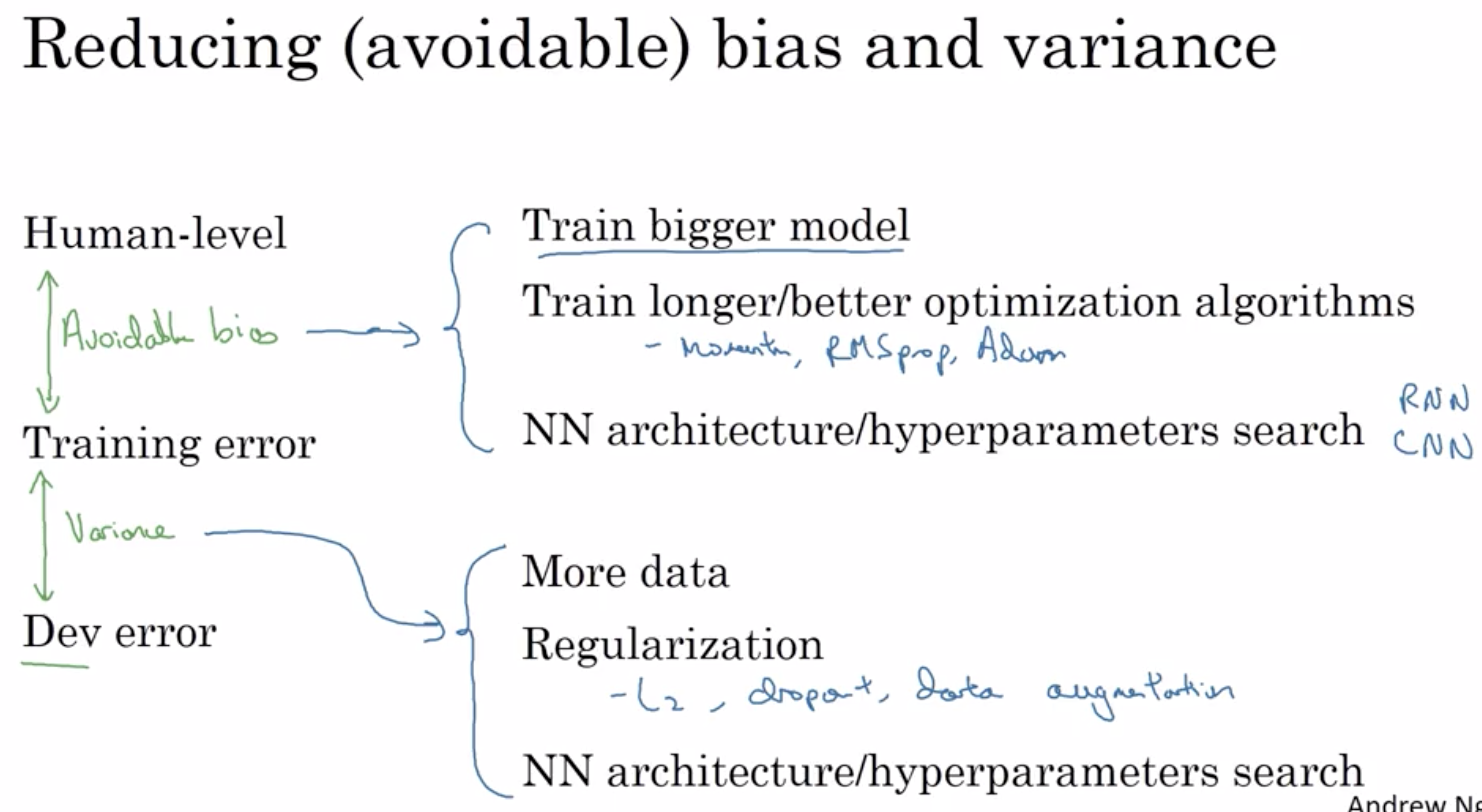
4.4 总结:如何提高你的模型表现
一般,认为一个有监督学习算法能发挥作用,基本上意味着,希望或者预设你可以做到两件事 第一是你可以很好地拟合训练集,你可以大致认为你能得到较低的可避免偏差。
第二点是 训练集的结果可以很好地,推广到开发集或者测试集 这就是说 方差不太大 从正交化角度来说 你看到的是 存在一组旋钮
可以修正可避免偏差的问题 比如训练更大的神经网络
或者训练更长时间 并且有另一组独立的方法
可以用来处理方差的问题 比如正则化或者获取更多训练数据