Welcome to MyBlog! This article was writed to take note my study of Machine Learning on Cousera.
1. 错误分析
什么叫表现上限:
拿大约100张分类错误的验证集图片<br />并进行手动检测 只需要数一数 看有多少张
验证集中标错的样本实际上是狗的图片 现在 假设事实证明 在验证集中分错的100张样本里<br />
有5%是狗的图片 也就是说 验证集中<br />分错的100张中有5张是狗 这意味着在这100张图片中
特指你分错的这100张 即使完全解决狗的问题<br />也只在这100张中多分对了5张 换言之
若只有5%的错误是狗照片 如果你在狗的问题上花了大量时间 最好的情况也就是 你的错误率
从10%下降到9.5% 对吗 这5%是错误里的相对下降值<br />因此是从10%下降到9.5%
那么你可能可以合理地判断出错误分析:
假设有别的事情发生了 假设 在验证集里错标的100张样本中 你发现他们中的50张实际上是狗的图像 所以50%是狗的照片 现在你可以更确定地把时间花在狗的问题上 在这种情况下 如果你真的解决了狗的问题 你的错误率可能将从这10%下降到5% 你可能会认为错误率减半是值得付出努力的 专注于减少被错误标识的狗 我知道在机器学习中 有时我们会贬低 手动操作或使用太多人工判断 但是如果你在构建应用系统
那么这个简单的计数过程 也就是错误分析 可以节省你很多时间 在决定什么是最重要的 或哪个方向最有希望 值得关注
2. 如何对待错误数据
1 当错误数据发生在 训练集
事实证明,深度学习算法 对训练集中的随机错误很稳健 只要你的错误,或者说错误标记的例子 只要这些错误不是那么偏离随机分布 而可能只是由标记的人偶然的疏忽造成的, 比如随机按下了错误的键 总之,如果这些错误是相当随机的 那么我们基本可以不管(这些错误) 不用花费太多的时间去纠正它们 当然了,仔细检查你的训练集和标签 并且纠正它们,肯定是无害的 有时候,这是很值得花费时间去做的, 但你也可以不做,只要总数据量够大, 而且实际错误标记的数据占比不高
2 这些错误标记的数据(对开发集和测试集)的影
一个比较推荐的做法是,在错误分析的过程中 增加一列,去统计 Y的标签错误的数量
如果这些错误对你评估算法在开发集上的效果 有很大的影响的话 那就继续做吧,花时间去纠正这些错误标签 但是如果没有太大影响 对你用开发集去评估模型 那你的时间最好不要花在这上面

3 如果你决定探究开发集 手动重新检查标签,并且尝试纠正一些标签 这里由一些额外的指南或者说原则去考虑
(1) 如果你要探究并纠正开发集中的一些问题 我会建议将这个过程也应用到测试集,以确保 它们依然服从同样的分布
(2)我强烈建议你考虑检查 你的算法准确预测和错误预测的例子(这个原则不常被使用,因为判断正确的数据太多)
(3) 训练集 和 开发/测试集,可能来自不同的分布

3. 如何快速构建一个新的系统
我的建议是
快速构建你的第一个系统 然后迭代 这个建议不那么适用
如果你处于一个 你经验丰富的领域 这个建议同样也不适用于 当有很多可以参考的学术论文 针对你正在研究的
几乎完全相同的问题 比如说 有很多学术文献研究人脸识别 如果你正在尝试建立人脸识别系统 你可以从一开始就打造一个复杂的系统 依托于大量的学术文献 但是 如果第一次
你正在研究一个新的问题 那么我建议你 真的不要考虑太多
也不要把你的第一个系统做得太复杂 只要建立一个快速的早期的系统
然后使用它 来帮助你确定一个优先级
如何来改善你的系统

4. 当training 和 test数据来自不同分布
方案一,将两个集合的数据混合在一起,再重新分配(建议不要采用方案一 因为它设置的开发集使你的团队致力于 优化一个与你实际关心的目标
并不相同的数据分布)
这样的数据分配有其优点和缺点 优点是这样一来你的训练/开发/测试集 都来自于同一分布 易于管理 而缺点 一个巨大的缺点是 仔细看看你的开发集
它有2,500个样例 但是大部分来自网页图片的分布 而不是你真正关心的
来自移动应用图片的分布
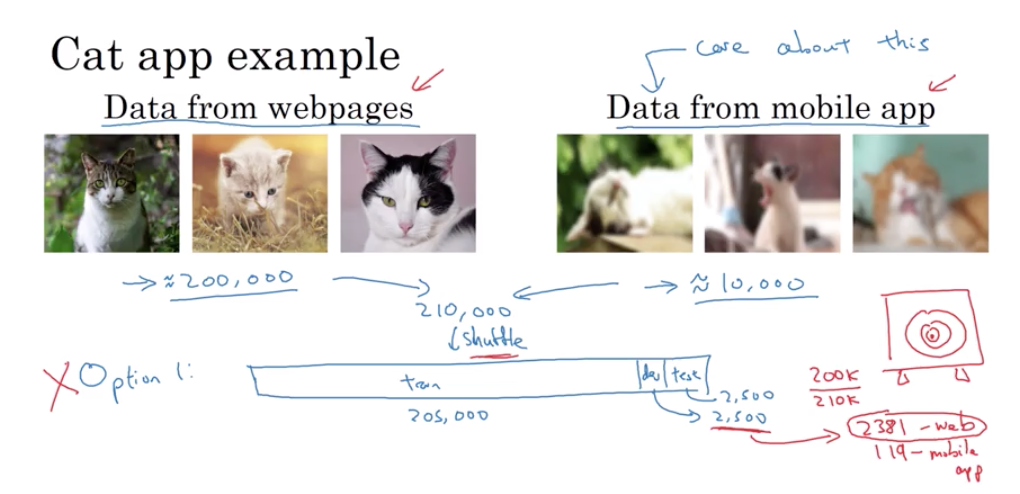
方案二:假设训练集仍然包含205,000个图片,练集包含200,000个网络图片 和5,000个移动应用图片 开发集包含2,500个移动应用图片 测试集也包含2,500个移动应用图片 按照这种方式划分训练/开发/测试集 其优点是你瞄准的是正确的目标 你在向你的团队表明
我的开发集数据来自于移动应用 而这正是你真正关心的图片的分布 让我们来建立一个机器学习系统 它在移动应用图片分布的表现的确很好 当然其缺点就是你的训练集的分布 不同于您的开发和测试集分布 但事实证明这样划分训练/开发/测试集 长期来说性能更好
5. 不匹配数据分布的偏差和方差
通过估计学习算法的偏差和方差 能帮你确定下一步工作的优先级 但当你的训练集 开发集 测试集 来自不同的分布时 偏差和方差的分析方法也会相应变化
这时误差分析要注意 当你从训练集误差 转移到开发集误差时 有两件事情变了 一 算法看到的数据只有训练集没有开发集 二 开发集和训练集数据分布不同 因为同时存在两个变量 我们很难判断 这9%的误差 有多少是因为 算法未接触开发集 而影响了方差 又有多少是 因为开发集的数据分布不同
为了辨识出这两个影响 如果你对这两种影响完全不了解 别担心 别担心 我们马上就会说到 为了梳理出这两个影响 我们需要新定义一组数据 叫做训练-开发集(training-dev set) 这是一个新的数据子集 我们要让它与训练集拥有同样的数据分布 但你不用直接拿它来训练你的网络 就是这样子
之前我们已经建立了训练集 训练集和测试集 如图所示 开发集和测试集属于同分布 训练集数据属于不同分布 我们要做的是将训练集随机混淆(shuffle) 取出一小块数据作为训练-开发集 如同开发集与测试集分布相同 训练集与训练-开发集也遵循相同分布
假设训练集误差为1% 训练-开发集误差为1.5% 但是开发集误差为10% 这就是方差偏小的问题 因为从已经见过的训练集数据 到未见过的训练-开发集 误差只增加了一点点 但是到开发集出现了跃增 所以这是数据不匹配的问题

6. 如何解决因为数据不匹配导致的误差
如果发现出现了严重的数据不匹配问题 我通常会人工地分析误差 并且试着去理解训练集与开发/测试集之间的差异 为了避免测试集上的过拟合 技术上对误差分析来说 你的关注点应该只是开发集而不是测试集
如果你的目标是使训练集与开发集更加相似 这样有什么解决方法呢? 其中一个方法是你可以通过 人工数据合成 让我们在解决汽车噪声问题的背景下讨论这个问题。
