Welcome to MyBlog! This article was writed to take note my study of Machine Learning on Cousera.
部分借鉴于博客
词嵌入
one-hot编码
這樣的表示法有個弱點是 它將每個字詞獨立看待 無法讓演算法能夠泛化運用至相關字詞 高纬度特征的优势

常用的视觉化演算法 t-SNE

來自 Laurens van der Maaten <br />和 Geoffrey Hinton 的論文为什么叫做词嵌入 word embedding
這些用到特徵化向量的表示法 如這些300維向量所用的表示方法 被稱作「嵌入」
我們這樣叫它的原因是 你可以想像一個300維度的空間 而當然, 我們畫不出300維的空間<br />
這裡用一個三維空間表示 然後取每一個字詞, 如「柳橙」 會對應到一個三維特徵向量
使得這個字被嵌入在這個300維空間上的一點 而「蘋果」被嵌入在300維空間上的另一個點 如何使用 词嵌入
实例
榴莲是一种罕见的水果, 在新加坡和其他少数节国家很流行。 但如果你为人名识别任务
设置了一个小的标签训练集, 你可能根本没有在你的训练集中看到
单词’durian榴莲’或’cultivator耕种者 我想严格来说,应该是a durian cultivator
一位种榴莲的耕种者。 但如果你学了一个单词嵌入, 它告诉你榴莲是一种水果, 它就像橙子一样,
并且告诉你耕种者和农民类似, 然后,你可能在训练集中见过 orange farmer橙子果民
从而得知durian⏎cultivator 榴莲耕种者可能也是个人。 因此,单词嵌入能够做到这一点的原因之一是 学习单词嵌入的算法 可以检查大量的文本主体,
也许是在网上找到的这些文本 所以你可以检查非常大的数据集, 也许会达到10亿字,
甚至多达1000亿字,这也是相当合理的。 大量的只含未标记文本的训练集学习迁移
你可以进行学习迁移, 你可以利用来自文本的信息, 这些大量未标记的文本可从网络上免费得到 去得出橘子、苹果和榴莲都是水果。
然后将该知识迁移到任务上, 如命名实体识别, 对于这个任务,你可能有 较小的已标记的训练集。 当然,简单起见, 我只画出单向RNN。 如果你确实要执行命名识别任务,则应该 使用双向RNN, 而不是我画的简单RNN。 但总而言之, 这就是如何使用单词嵌入来进行学习迁移 :

- 第一步是从大量的文本语料库学习单词嵌入, 或者可以从网上下载已经训练好的单词嵌入。
- 然后你可以把这些单词嵌入迁移 到有着更小的已标记训练集的任务上。 然后用这个300维的词嵌入,来代表单词。 还有一点好处是你现在可以使用 相对较低维的特征向量。 不用1万维的one hot向量, 你现在可以改用300维向量。
- 最后,当你在新任务上训练你的模型时, 比如,在较小标签数据集的命名识别任务上, 你可以选择性的去继续微调参数, 继续用新数据调整单词嵌入。 (实战中,只有任务2具有相当大的数据集时, 才会执行此操作。 如果第二步带标签的数据集很小, 那么通常, 我不会继续微调单词嵌入。)
词嵌入迁移的适用情况
如同在其他迁移学习设置中看到的, 如果您正在尝试 从某个任务 a 转移到某个任务 B, 迁移学习过程在这种情况下最有用的, 就是当你碰巧 对A有很多数据集,B有相对更少的数据集。 对于许多 NLP 任务, 这是正确的,然而对于 一些语言建模和机器翻译,就不一定了。
词嵌入的作用 - 类比推理
词的词组相关性判断(类比)
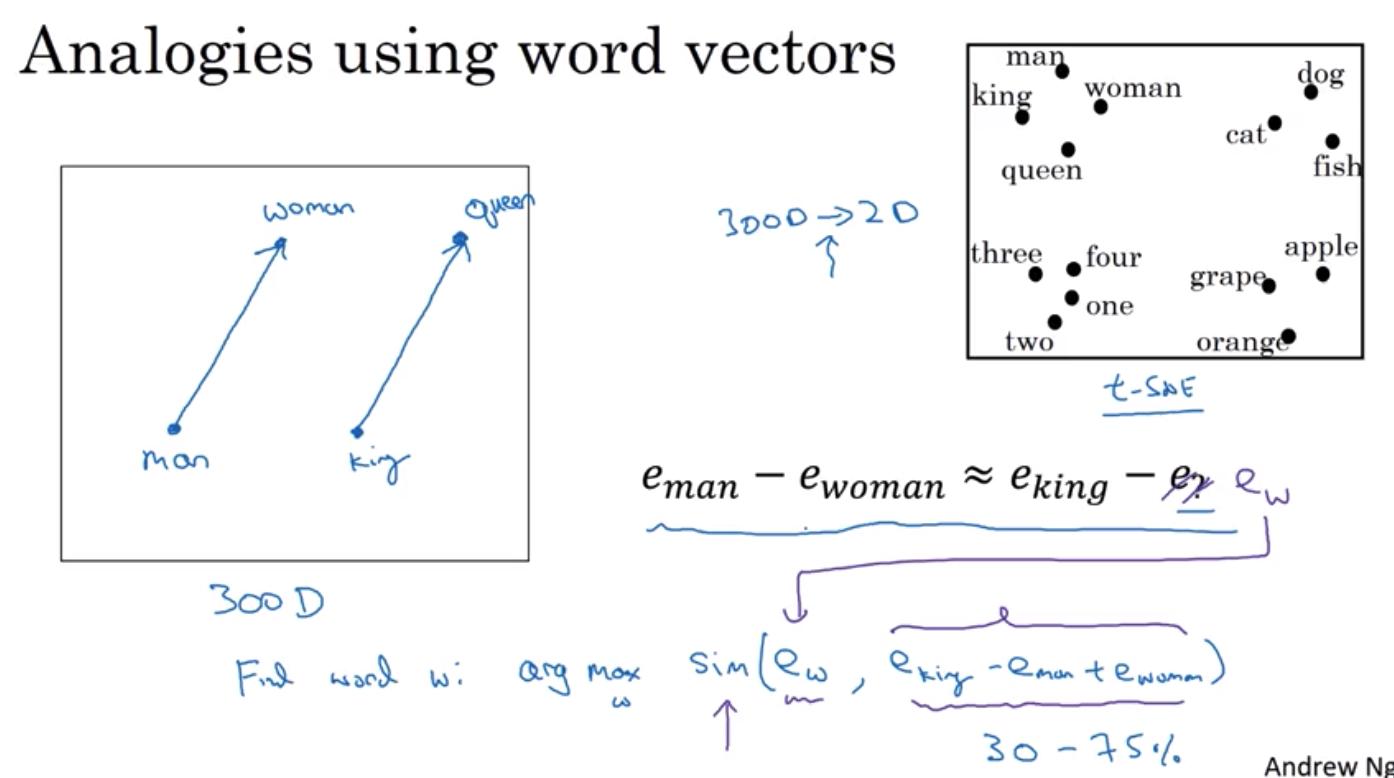
词嵌入可以帮你找到一组词汇中你想要的特定的词语 假设我提出了一个问题
男人对应女人那么国王对应什么呢 
注意:诸如t-SAE 之类的算法来可视化单词 t-SAE做的是,它处理300维的数据 然后以非线性的方式映射到2维空间 因此t-SAE的学习过程是一个非常复杂并且 非线性的映射 所以在t-SAE映射以后,你不应该期望这种类型的 平行四边形关系, 就像我们在左边看到的, 是有效的
余弦相似度 和 欧几里得距离
这就是余弦相似度的来源,并且它对于 类比推理的应用是很有效的
如果你想的话,你也可以用平方距离或 欧几里得距离,u-v平方
技术上来说这是对非相似度的测量,而不是 相似度的测量
所以我们需要利用它的不利因素,并且也可以应用得很好
虽然我看到余弦相似性被使用得更频繁一些
这两者最大的不同在于 它是如何规范化向量u和v的长度的
因此, 嵌入词的一个显著的结果是 它们能够学会的类比关系的普遍性 比如说它可以学习男人对应女人之于男孩对应女孩 因为男人和女人之间的向量差
与国王与王后以及男孩和女孩之间的差别是相似的,主要是性别
它也知道Ottwa(渥太华)是加拿大的首都 正如Nairobi(内罗毕)是肯尼亚的首都一样
所以城市首都对应着这个国家中的一个名字 它可以学习大对应更大,正如高对应更高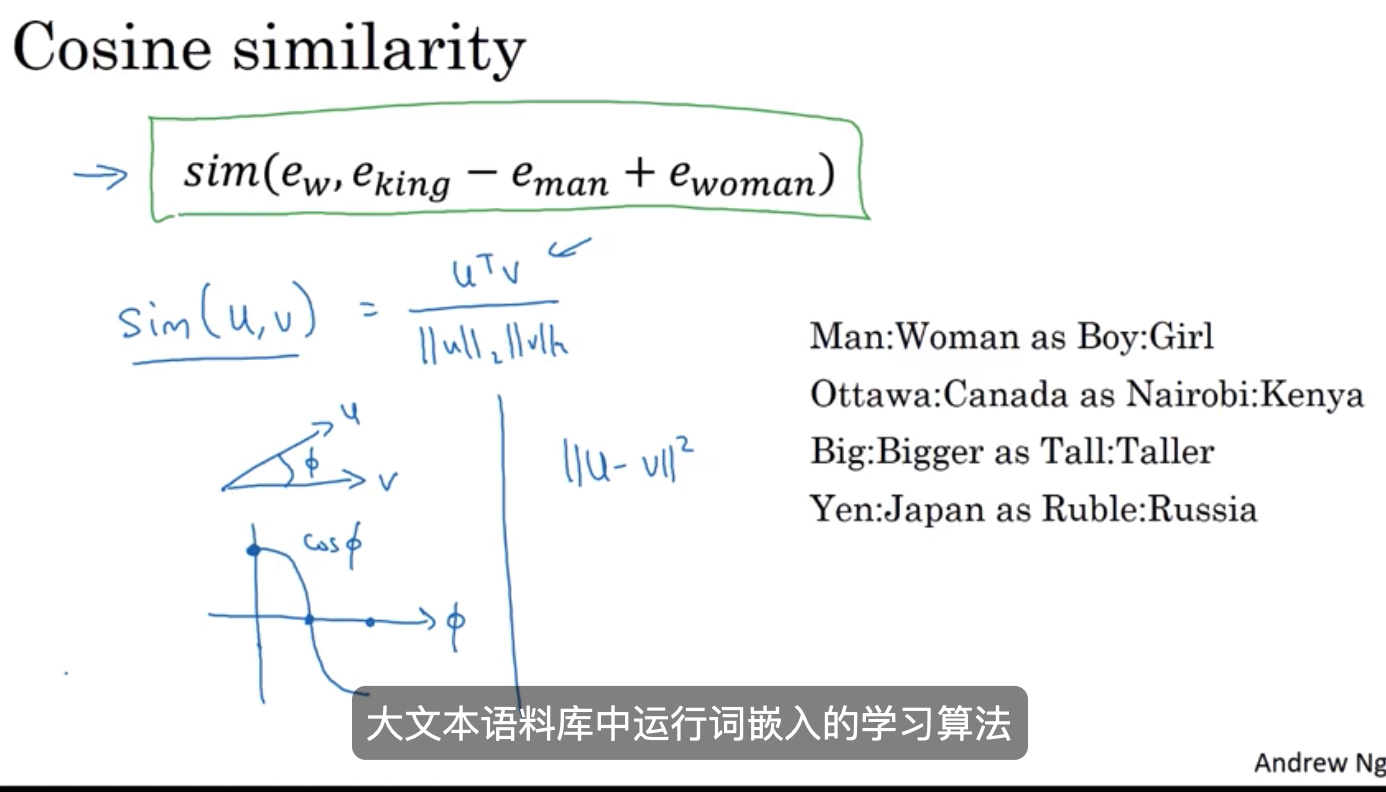
Embedding matrix 嵌入矩阵
词嵌入 和 one-hot编码 的符号和图表示

learning word embeddings 训练和学习 词嵌入的方法
神经网络语言模型 学习word-embedding
在这个视频中你们看到了语言建模问题 这导致机器学习问题的不同角度
你输入像最后四个单词这样的上下文, 然后预测一些目标词
如何看待这个问题让你可以学习输入词嵌入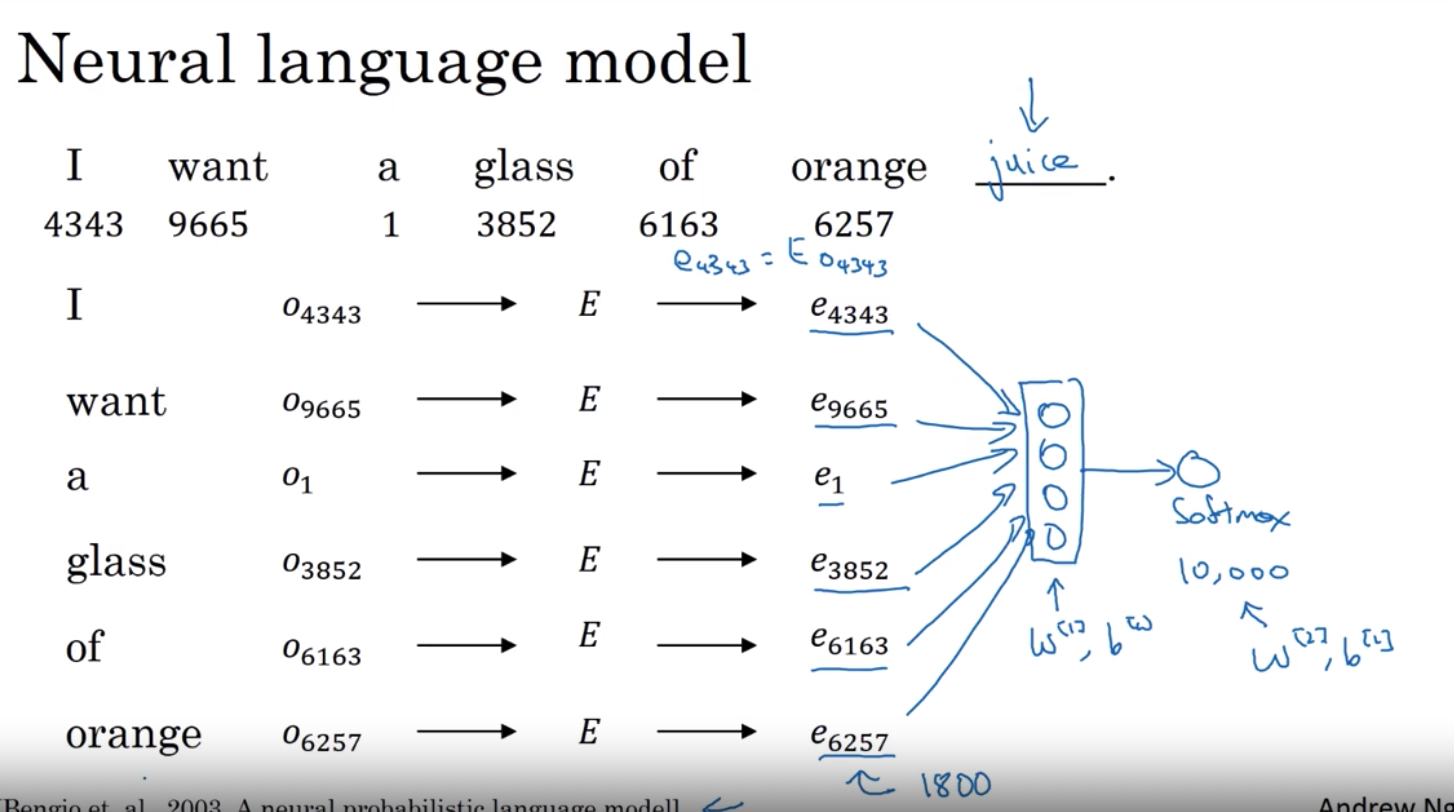
上图中的E就是我们要训练的词嵌入!
研究人员发现, 如果你真的想建立一个语言模型 用最后几个单词作为上下文语境是很自然的 但是, 如果你的主要目标是真正学习词嵌入 那么你可以使用所有这些其他的上下文并且他们 也会产生非常有意义的词嵌入
skip-grams

这就是所谓的skip-gram模型,因为输入一个单词 比如orange,它会试图跳过一些单词去预测另一些单词 从左边或者从右边跳过 预测出现在语境词前后的词,会是什么
现在,使用这个算法还有几个问题需要解决。 最主要的问题是计算速度 特别是对于softmax模型, 我们每次都要计算这个概率 这就需要在你的词汇表中对所有1万个单词进行求和 也许一万个词汇并不是很糟糕 但如果使用的是大小为10万或100万的词汇表, 每次都要对这个分母求和,就会变得很慢。
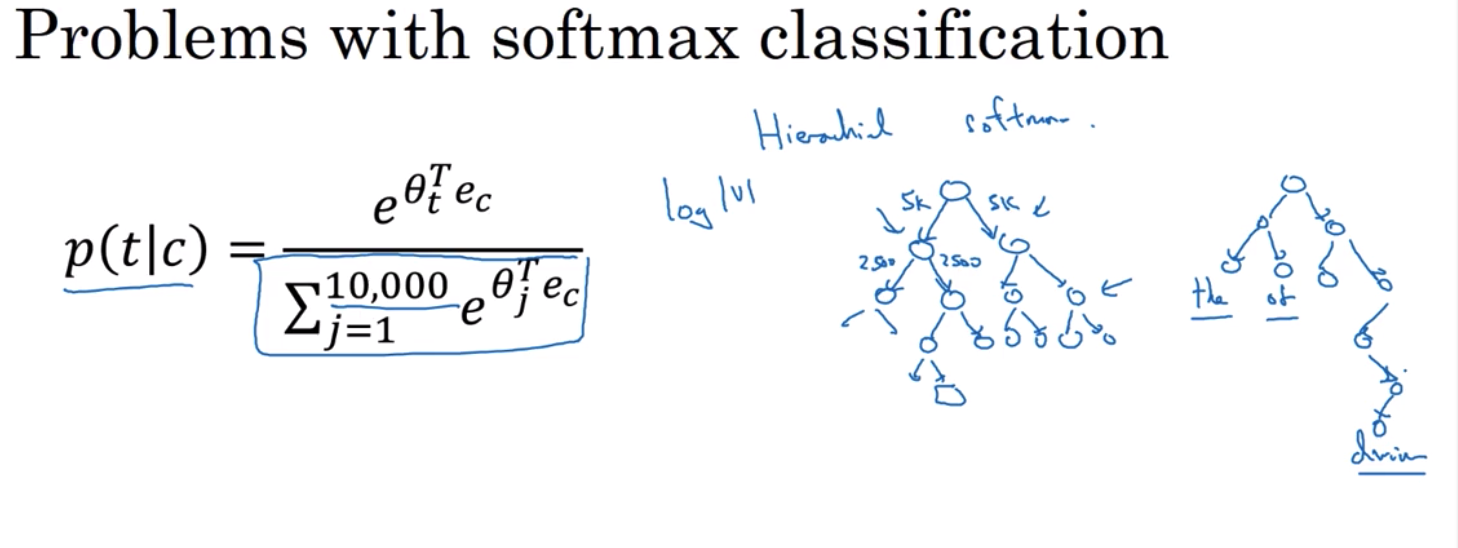
使用分层的softmax分类器 它的意思是 并不是在一次计算中把它分成一万个类 想象你如果有一个分类器 它会告诉你目标单词是否在词汇表的前5000个单词里 或者是在后5000个单词里 假设这个二分法分类器告诉你,它在前5000个单词里 第二个分类器告诉你,它在词汇表的前2500个词汇里 或者在后2500个词汇里,诸如此类 直到最后,你终于分清楚它究竟是什么单词 就像这棵树上的叶子,因此这么一个像树一样的分类器 这个树上的每一个内部节点,都可以用一个二元分类器来表示,比如逻辑分类器 这样你就没必要对所有10000个单词求和 仅仅为了一个分类 事实上,使用像这样的一个分类树的计算代价 是根据词汇表大小,按对数函数形式增长的,而不是按线性增长的 这就是分层softmax分类器 我想提到的是,在实际应用中,分层softmax分类器并不会 使用一个完美平衡的树,或者说完美对称的树 每个分支的左右两侧有着同样数目的单词 事实上,分层softmax分类器可以被设计成 常见的词汇都在顶端 而像durian这样不怎么常见的词汇,就被隐藏的很深 因为你经常看到常见的单词 所以你或许只需要几次遍历,就能找到常见的词汇,比如the和of 但是你很少会看到像durian这样罕见的词汇 它就会把它埋在树的深处,因为你没有必要经常去到那么深 因此有许多启发式的方法 来建立这棵树,这棵你用来建造分层softmax分类器的树
负采样法 negative sample
训练过程
想象这是有10,000个二进制逻辑回归分类器 但是,并非要在每次迭代中 训练全部10,000个分类器 我们只训练其中的5个 也就是对应于实际的目标词语的那个 以及对应于其他4个 随机抽取的负样本的分类器 这就是k等于4时的情形 那么,不同于训练一个非常难于训练的 巨大的具有10,000个可能结果的Softmax模型, 我们将它转换为 10,000个二元分类问题 它们每一个计算起来都特别容易 并且在每次迭代中,我们只训练其中的5个, 或者更一般地说 其中的k+1个,k个负样本,1个正样本 这就是为什么这个算法的计算成本显著更低 因为你在训练k+1个逻辑回归模型 或者说k+1个二元分类问题 它们在每次迭代中计算起来都相对容易 而不是训练一个具有10,000个 可能结果的Softmax分类器 在这周的编程练习中,你将有机会 来熟悉这种算法 这种技巧叫做负采样法,因为你做的正是 得到一个正样本,”橙子“,然后”果汁“ 然后你会故意地生成一些负样本 这就是为什么它叫做”负采样法“ 你将用这些负样本来训练4个二元分类器

采样方法

根据经验,他们认为最好的方法是 采用这种启发式的值,也就是介于 从经验频率分布中采样,即 观察到的英语文本中的分布, 到从均匀分布中采样 他们所做的,就是依词频的3/4次幂 来抽样 那么例如f(w_i)表示某个观察到的 英语中的词频 或者说你训练集中的词频, 那么取它的3/4次幂 这样它就介于取均匀分布 和取经验分布的 两个极端之间
GloVe word vectors(特点是简单)


从特征角度看待词向量
你无法保证用来表示特征的那些坐标 可以轻易地和人类可以 容易理解的特征坐标联系起来 尤其是,第一个特征可能是包括了性别、 皇室属性、年龄、食物、 价格、尺寸、 是名词还是动词 等等这些特征的一个组合 因此要给单个元素、嵌入矩阵的单个行 一个人性化解释是非常困难的 但尽管有这种线性变换 我们在描述类比的时候用到的 平行四边形图,仍然是有效的 因此,尽管有这种特征间可能的任意的线性变换 表征类比的平行四边形图仍然是有效的

词嵌入的应用 - 情感分类
希望本节视频能给你一种感觉 一旦你从学习了一个词嵌入向量<br />
或从网上下载了一个词嵌入向量 它可以让你相当迅速地构建出<br />非常有效的自然语言处理系统词嵌入的偏见
机器学习和AI算法越来越受人信任 可以用来帮人做出非常重要的决策 所以我们需要尽可能确保
算法中没有我们不希望看到的偏见,如性别偏见、种族偏见等 这节课我想教你一些方法
来减少或消除在词嵌入中的这些形式的偏差 
- 那如何才可以明确对应偏见的方向呢? 对性别而言,我们可以将词向量he 减去词向量she,因为他们是按性别来区分不同的 符号为e_male-e_female 取相类似的,然后取平均值对吧 并采取一些这些差异,基本上对他们去平均数。 这能让你明白在这个案例中应该得出一个怎样的结果 这个方向是性别的方向,即偏差方向
- 下一步就是中立化 对于每一个没有定义的词,通过映射来摆脱偏差 有些词本来就带有性别的含义 所以像grandmother grandfather,girl,boy,she,he, 都是本来就有性别相关的定义 然而像其他的词,如doctor babysitter,这些词是性别中性词 在很多情况下,你也许希望doctor babysitter是中性的或者说是 性别导向为中立的
- 最后一步叫均匀化 你有一对词,比如grandmother和 grandfather或girl和boy,你希望 词嵌入中唯一的差别是性别 那为什么你想这么做呢? 在这个例子中,距离也就是相似度 在babysitter和grandmother之间的距离 比babysitter和grandfather之间的要小 这会加强一种不健康 不希望看到的偏差, 即:grandmother之于babysitter 多余grandermother之于grandfather 所以在最后平均化这一步中 我们希望确保的是像grandmother, grandfather这类词 有相似性,有相同的距离