Welcome to MyBlog!
1. 中文分词的演变
1.1 查字典

但是它毕竟太过简单,遇到稍微复杂的问题就无能为力了。
1.2 最少词数的分词理论

无法解决二义性问题
1.3 统计语言模型
1.3.1 统计语言模型分词方法 的提出

1.3.2 统计语言模型分词方法 的数学概括

1.3.3 实现技巧

1.3.4 动态规划
1.3.4.1 什么是动态规划
动态规划:就是已知问题规模为n的前提A,求解一个未知解B的一种方法。


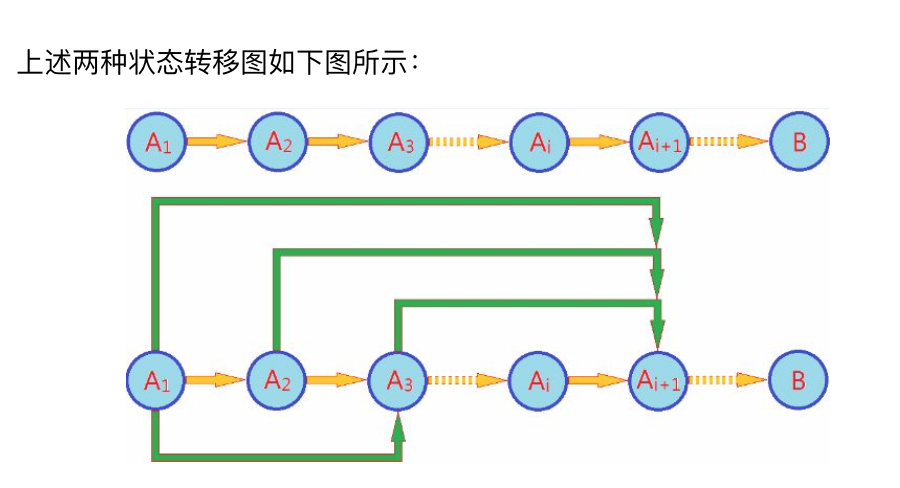
1.3.4.2 设计思路

无后效性:某阶段的状态一旦确定,则此后过程的演变不再受此前各种状态及决策的影响1.3.4.3 算法实例

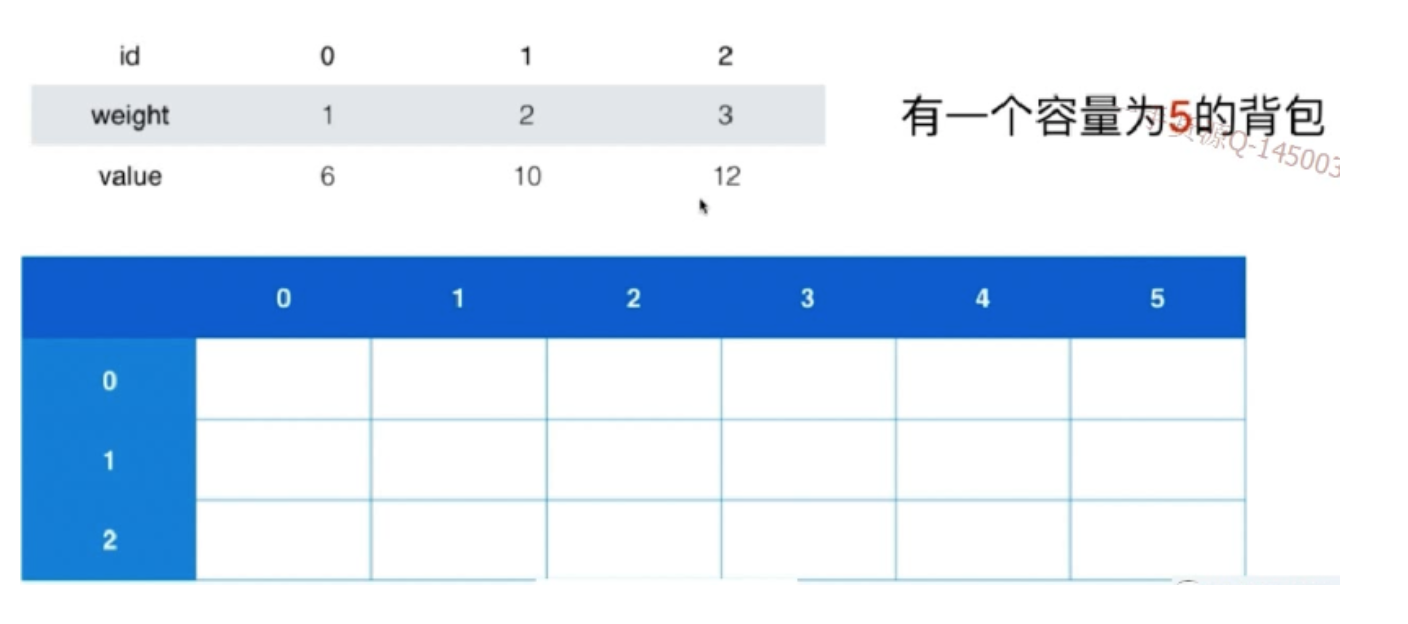
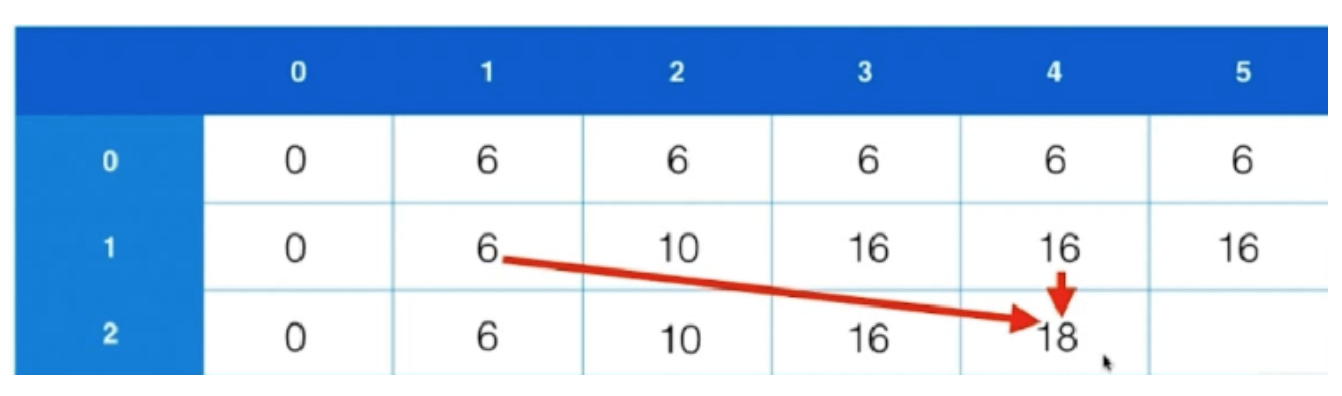
1.3.4.4 维特比算法
维特比算法是一种特殊的但应用最广的动态规划算法。利用动态规划可以解决任何一个图中的最短路径问题,而维特比算法则是针对一种特殊的图——篱笆网络的有向图的最短路径问题提出的。之所以重要,是因为凡是使用隐马尔可夫模型描述的问题都可以用它来解码。
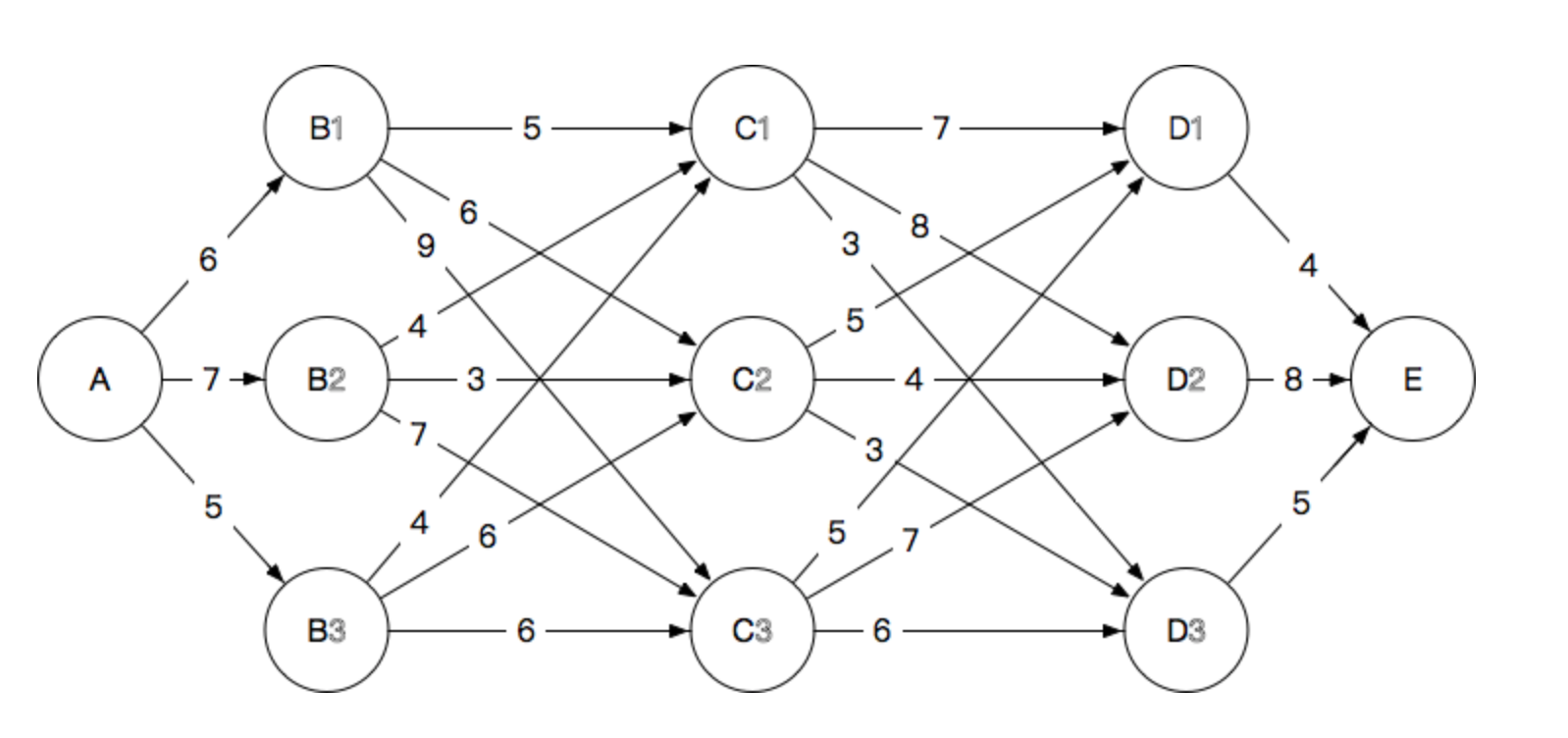
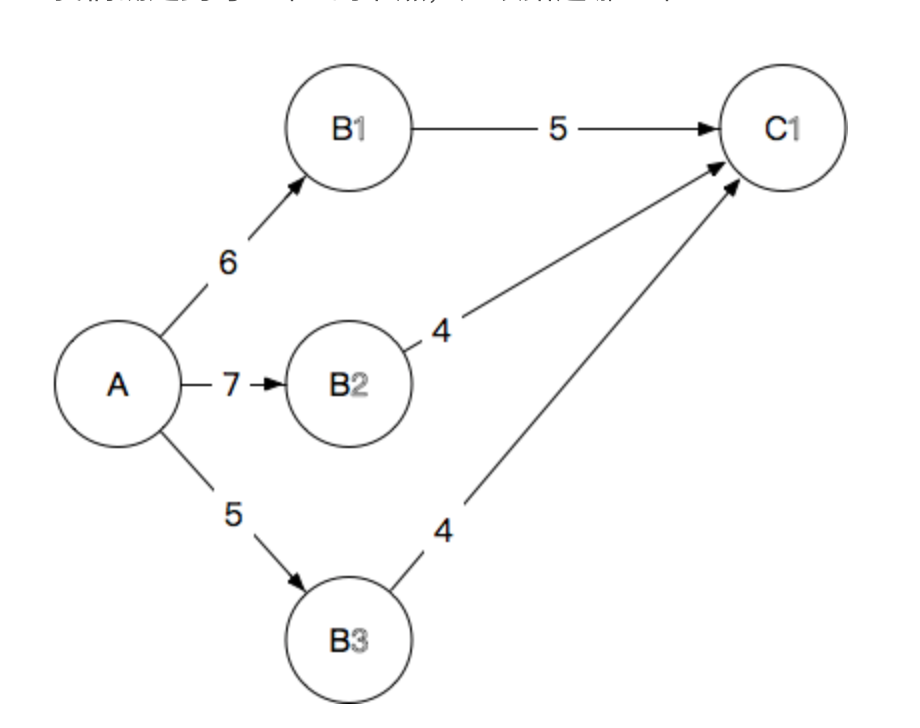
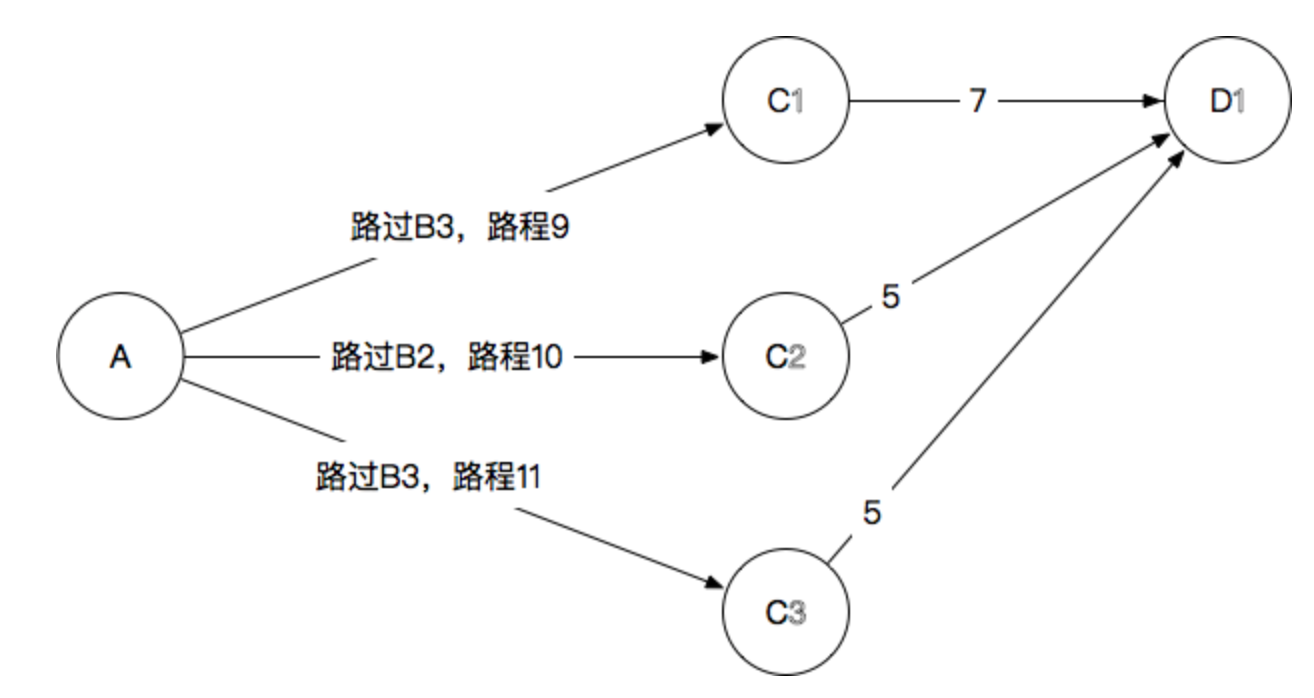
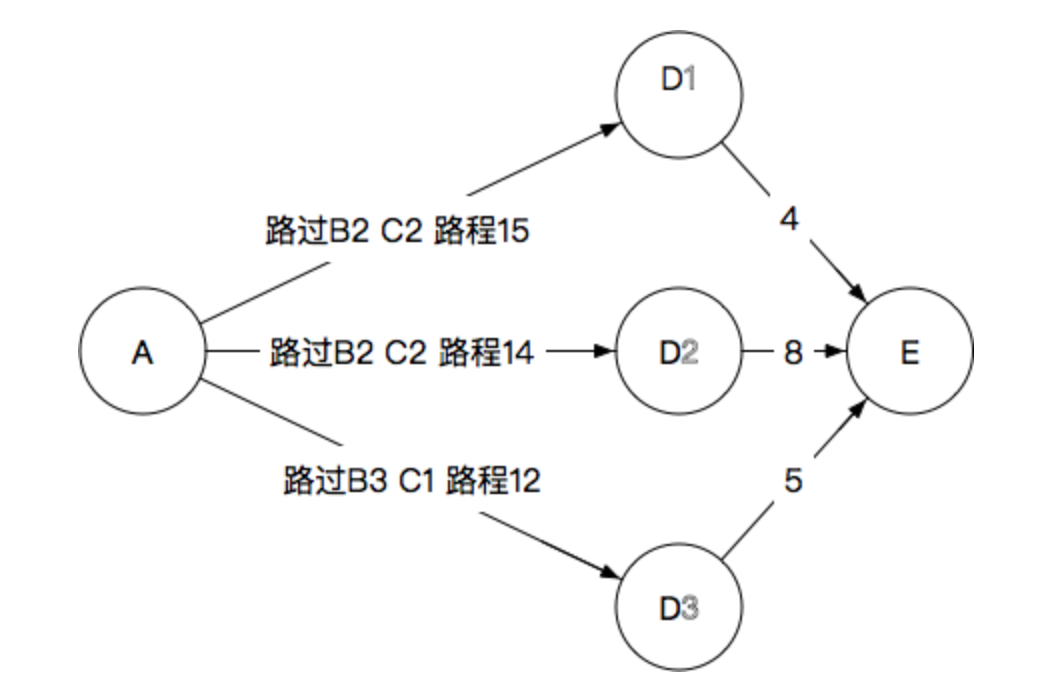
1.3.5 统计语言模型分词方法的 局限性

2 延伸阅读: 工程上的细节问题
2.1 分词器 准确性的问题
如何衡量分词结果的对与错,好与坏看似容易,其实不是那么简单。说他容易,是因为只要对计算机分词的结果和人工分词的结果进行比较就可以了。说他不容易,是因为不同的人对同一个句子可能有不同的分词方法。比如“清华大学”。


2.2 导致人工分词不一致性的原因
2.2.1 颗粒度的理解

作者不去强调哪一种颗粒度更好,而是指出:在不同的应用中,会有一种颗粒度比另一种更好的情况。
比如在机器翻译中,一般来讲,颗粒度大翻译效果会更好。比如“联想公司”作为一个整体,很容易翻译为:lenovo,如果分词时把他们分开了,就翻译错误了,联想会被翻译为:association。
但是在另一些应用中,比如网页搜索,小的颗粒度比大的颗粒度更好。比如“清华大学”这四个字作为一个词,在对网页分词后,它是一个整体了,当用户查询“清华”时,是找不到清华大学的,这就错误了。
2.2.2 解决方案
2.2.2.1 原理

2.2.2.2 实现方法
- (1)首先需要一个基本词的词表 和 一个复合词的词表
- (2)根据基本词表 和 复合词表,各构建一个语言模型L1 和 L2
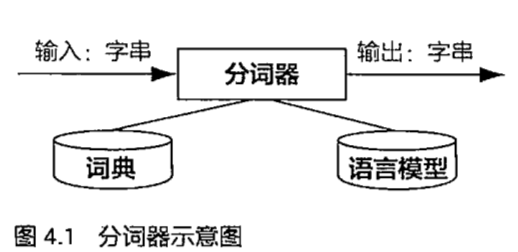
- (3)根据基本词表和语言模型L1,对句子进行分词,就可以得到小颗粒度的分词结果了。对应下图的分词器,输入的是字串,输出是词串。
- (4)在第三步的基础上,再用复合词表和语言模型L2 进行第二次分词。就可以得到大颗粒度的分词结果。对于下图的分词器,输入的是基本词串,输出的是复合词串。