Welcome to MyBlog! This article was writed to take note my study of Machine Learning on Cousera.
部分借鉴于博客
1 数学符号
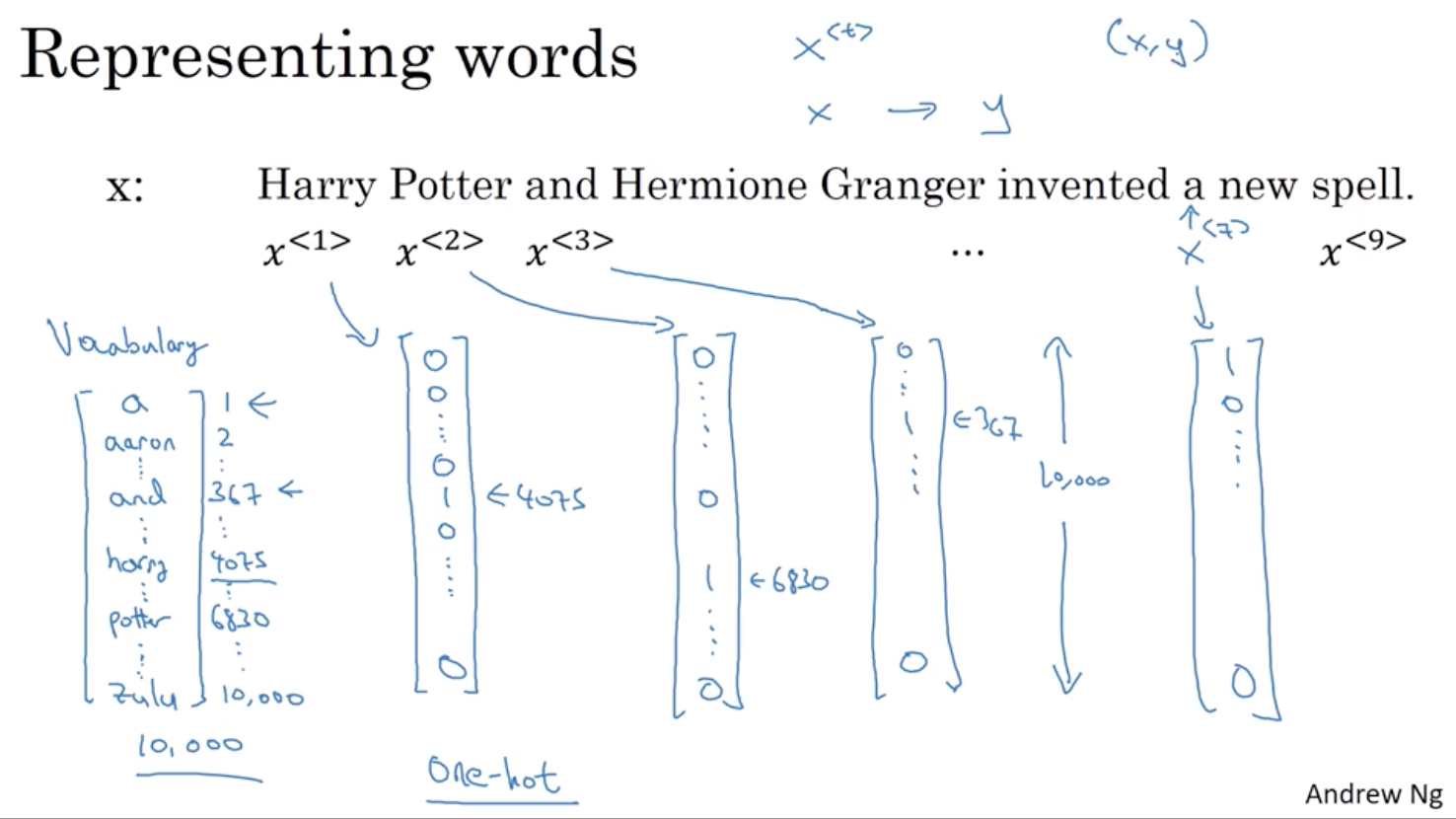
2 标准序列模型
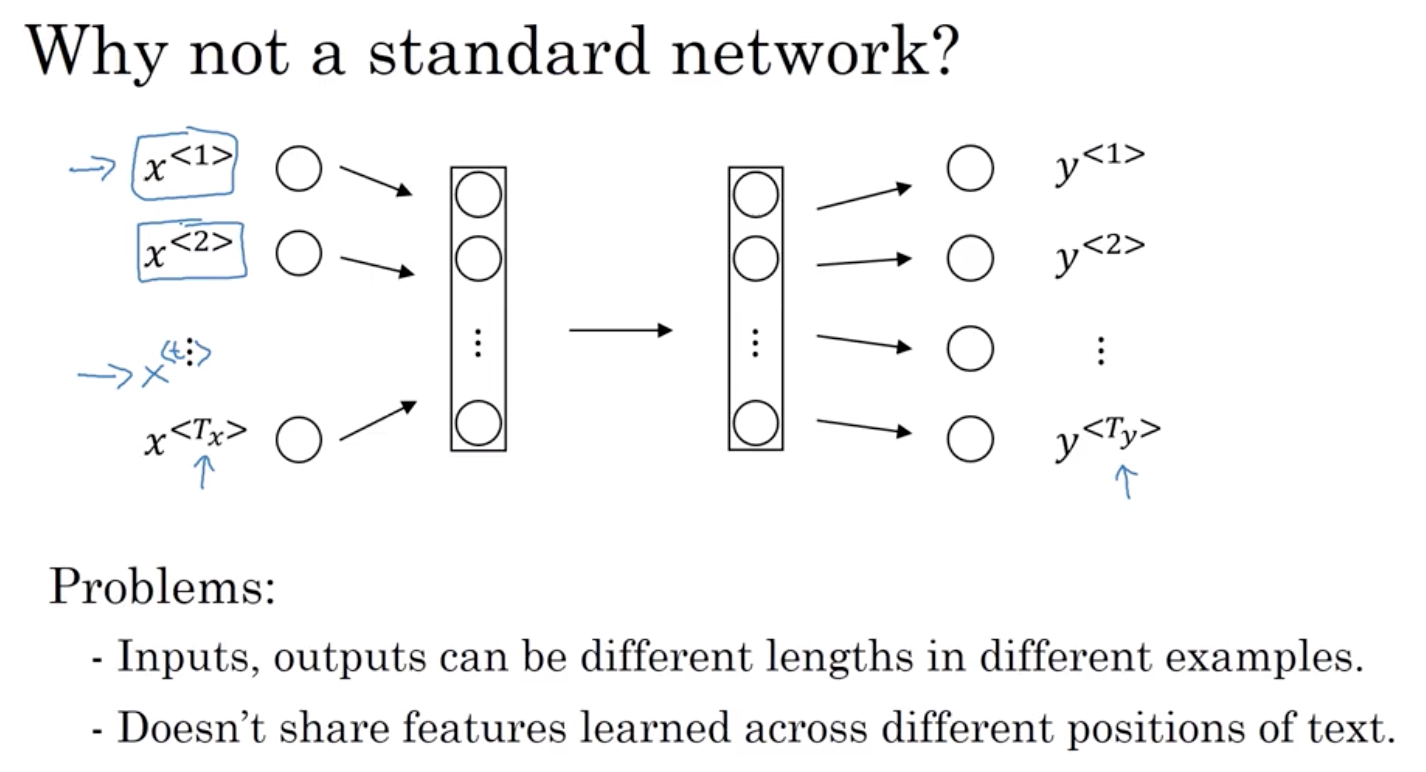
2.1 为什么不用标准神经网络
第一点,输入和输出对于不同的例子会有不同的长度 所以,它不是像每一个例子有相同的输入长度 Tx 或有最大的 Yy 值
或许每一个句子都有一个最大长度。 也许你可以填充或用零填充每一个输入 到最大长度,
但是,这似乎始终不是一个好的表示方法
第二点更严重,那就是 像这样的朴素神经网络结构 它并不会共享那些从不同文本位置学到的特征。 尤其是神经网络学到了经常出现的词汇 如果它出现在了位置1, 就会有标识指出这是人名的一部分 因此,这并不好。 如果它自动计算出经常出现 在其他位置 xt 依然能够表明这可能是一个人名 这也许和你在卷积神经网络课程 中看到的过程很相似 你想要的从图像的一部分学到的模式 来快速生成图像的其他部分, 我们希望在序列数据可以实现相似的效果。
2.2 循环神经网络
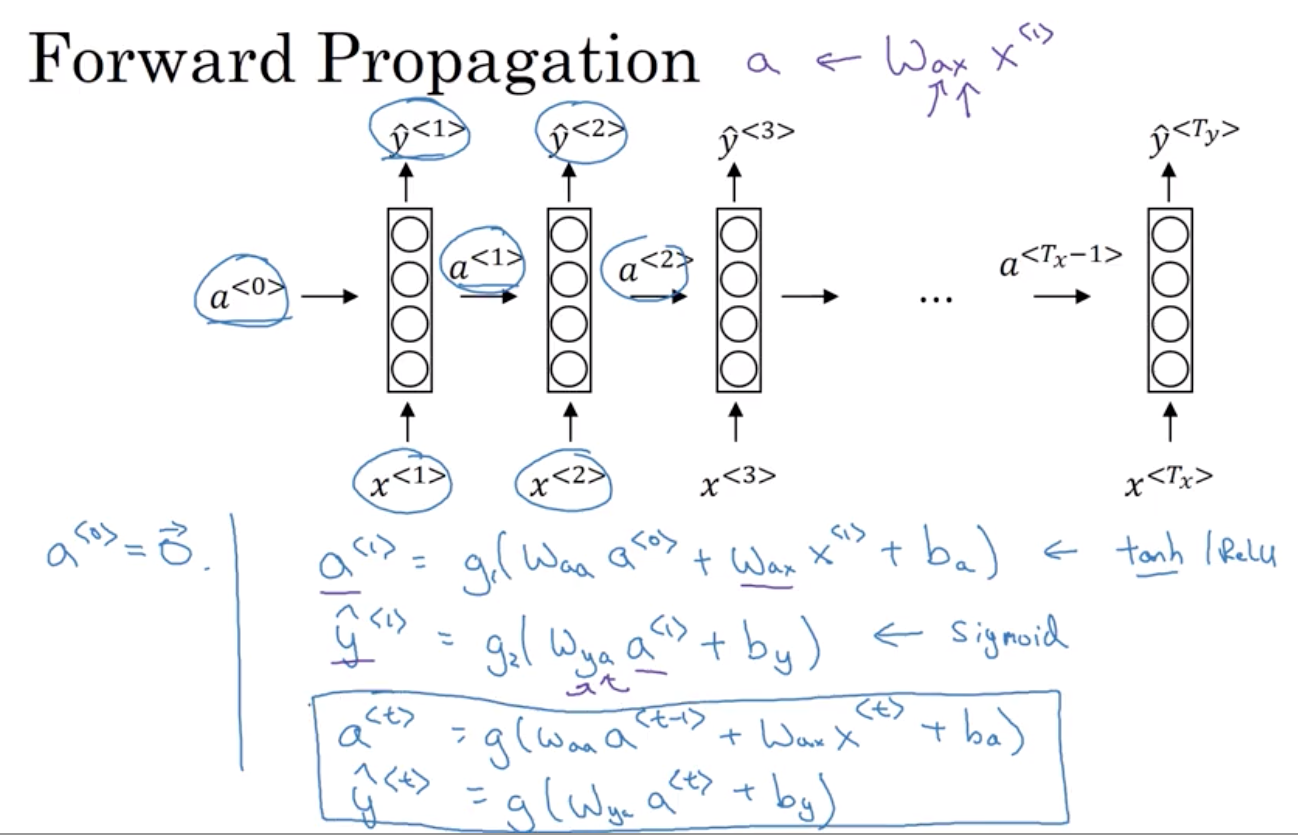
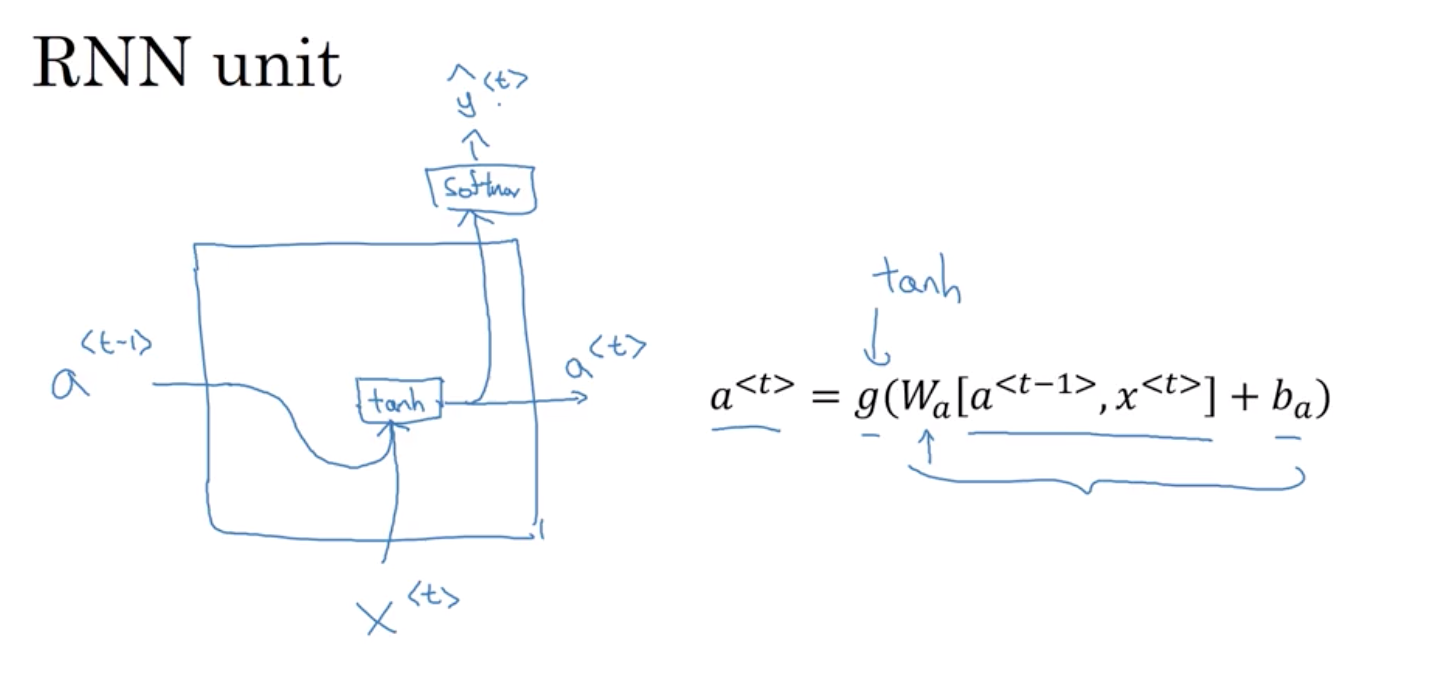
循环神经网络从左向右扫描数据 每一步,它所用的参数是共享的 所以会有一组参数, 我们将在下一页详细描述。 但是控制从x1到隐藏层的连接 是一组参数,我们用W_ax表示它们 这一组W_ax参数同时 也会被用于每一个步骤 我想我可以在那里写上W_ax 激活函数,各层间水平的链接是由 一组参数W_aa来控制 同样的W_aa也将被用于每一个步骤中 同样,W_ya控制输出预测 我将在下一张幻灯片中详细叙述 这些参数是如何运作的 那么,在循环神经网络中 当预测y3时意味着什么?

这种神经网络结构的一个限制 那就是在一确定的时间内预测
只使用输入或使用输入序列中之前信息 但不使用序列中后面的信息 我们将在稍后的视频中讨论
双向递归神经网络或 BRNNs 但现在但现在 这种简单的单向神经网络体系结构
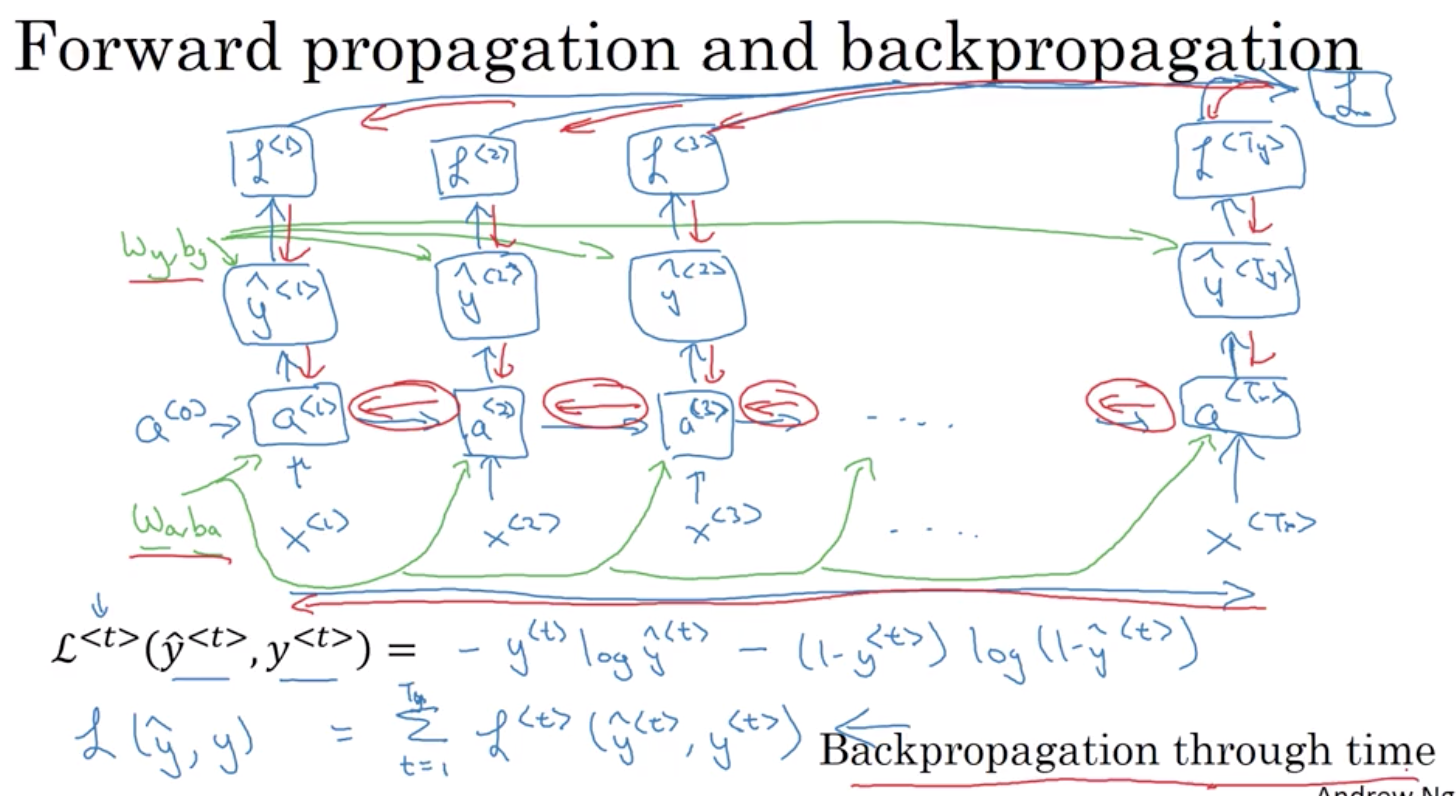
就足以解释这些关键概念了2.3 前向传递过程
Waa 和 Wax是共享的,被用于每一个步骤
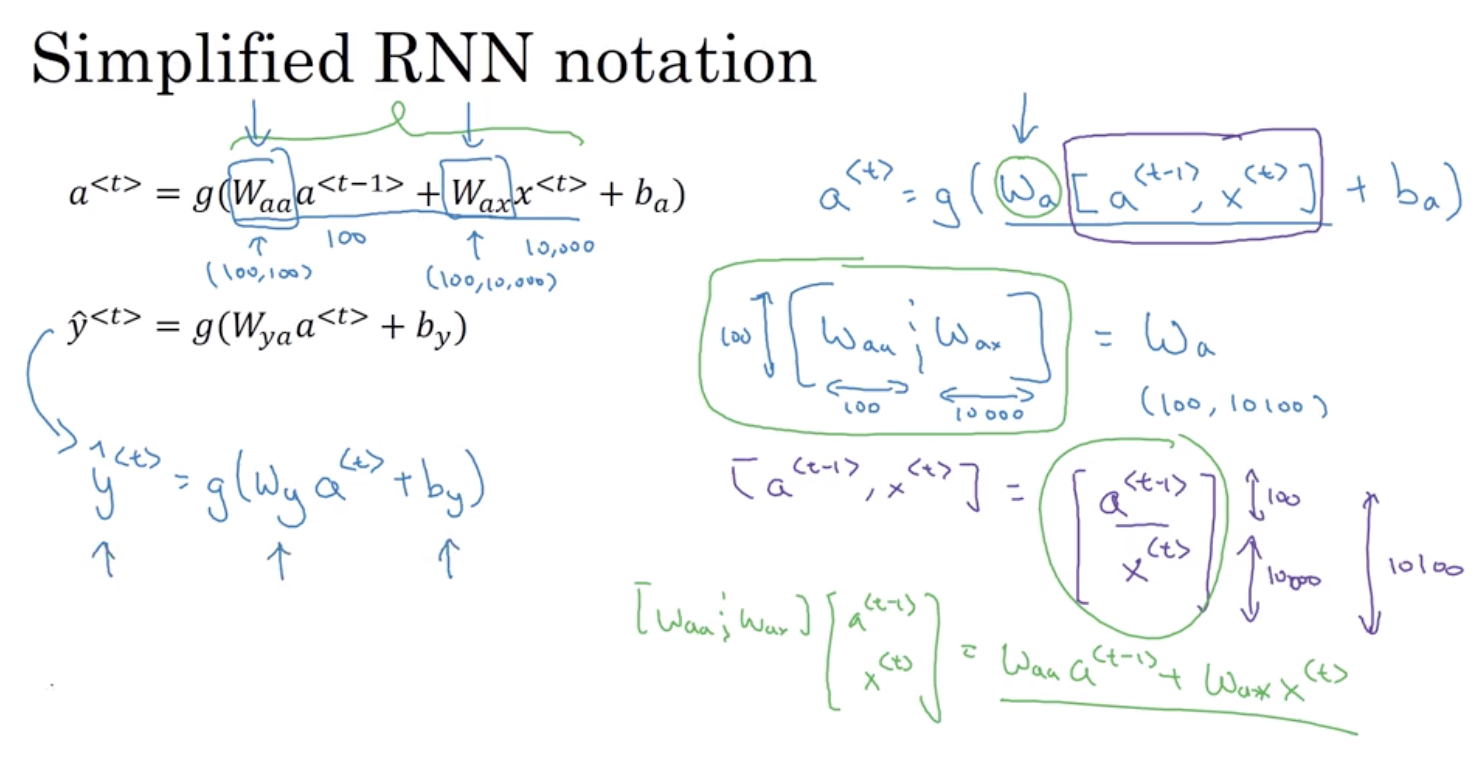
2.4 反向传递过程
3 不同类型的RNN
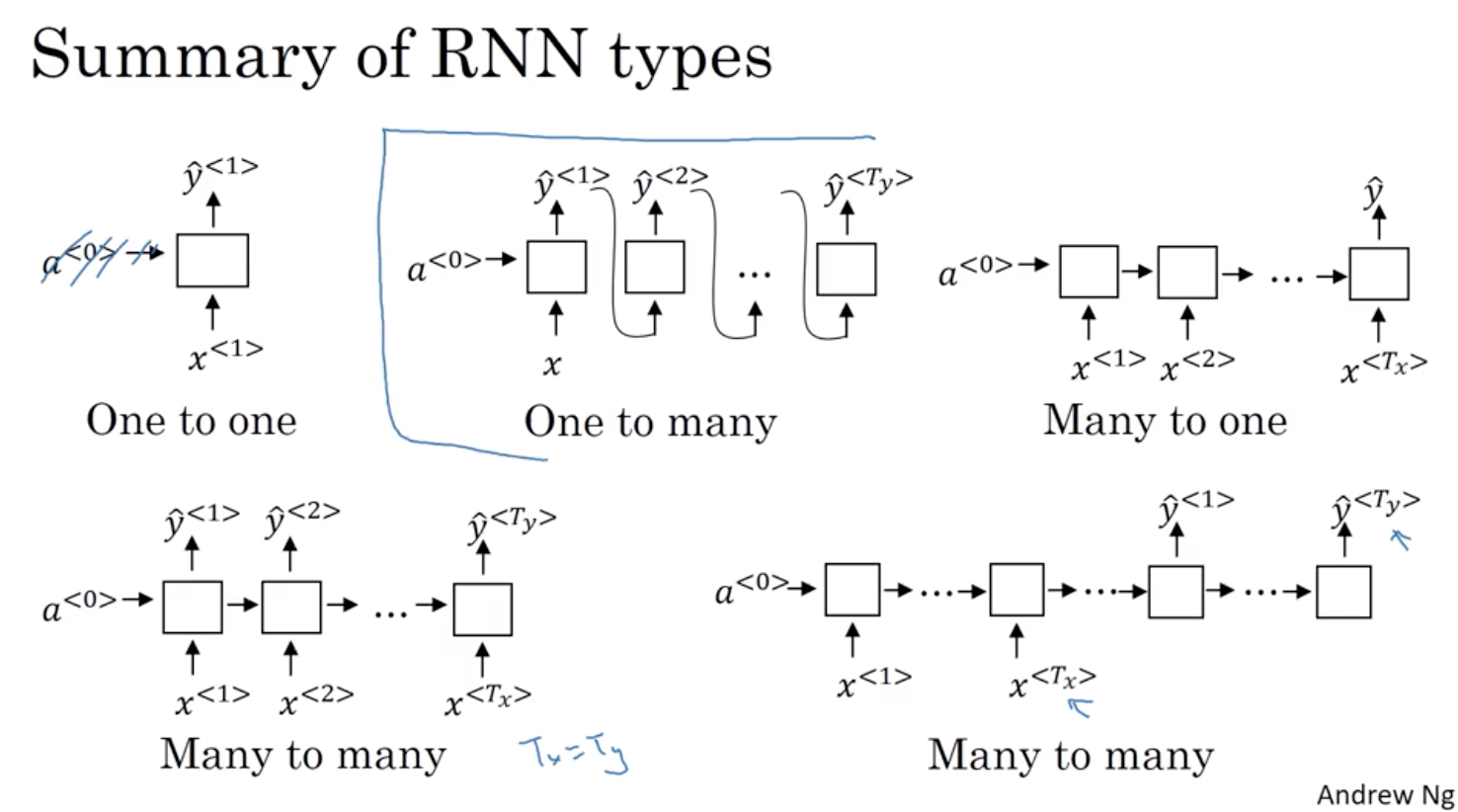
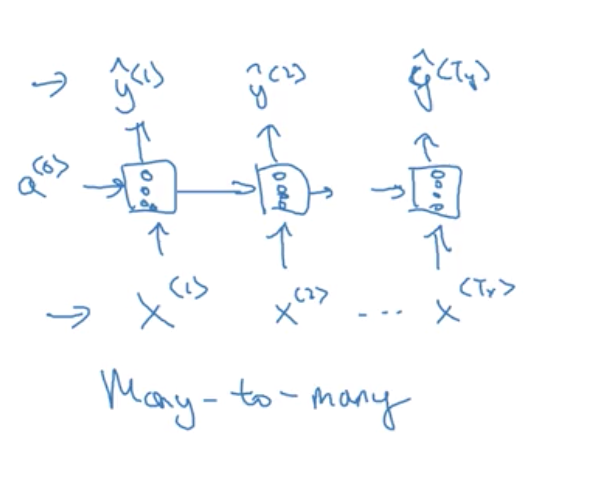
(1)输入和输出的数量相同
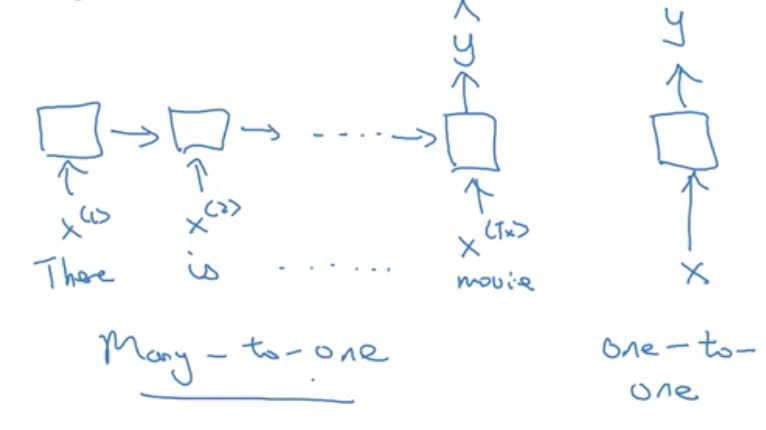
(2)多对1:假設,您想要來解決情緒分級問題 這裡的 x 是一段文字 可能是電影評論說 “這部電影沒啥看頭” (There is nothing to like in this movie) 所以 x 是一個序列 而 y 或許是一個數字從 1 到 5 或者 0 或 1
(3)1对多:一個一對多神經網路架構的例子是音樂產生器 實際上,您將自己建置一個這種網路 在這個課程程式練習裡,您將會有一個神經網路 輸出一些音符相對於一段音樂 而輸入 x 可能只是一個數字 告訴它您想要什麼類型的音樂, 或者是您想要音樂的第一個音符 如果您不想輸入東西 x 可以是空 (null) 輸入,也可以是零向量 這種神經網路架構裡,您的輸入 x 然後您的 RNN 輸出 第一個值,然後 在沒有任何輸入下做輸出 第二個值,然後繼續下去 第三個值,等等 直到您合成了這段音樂的最後一個音符
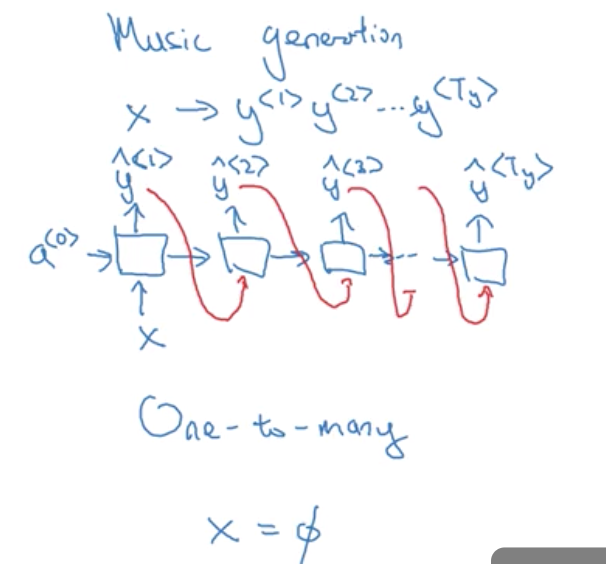
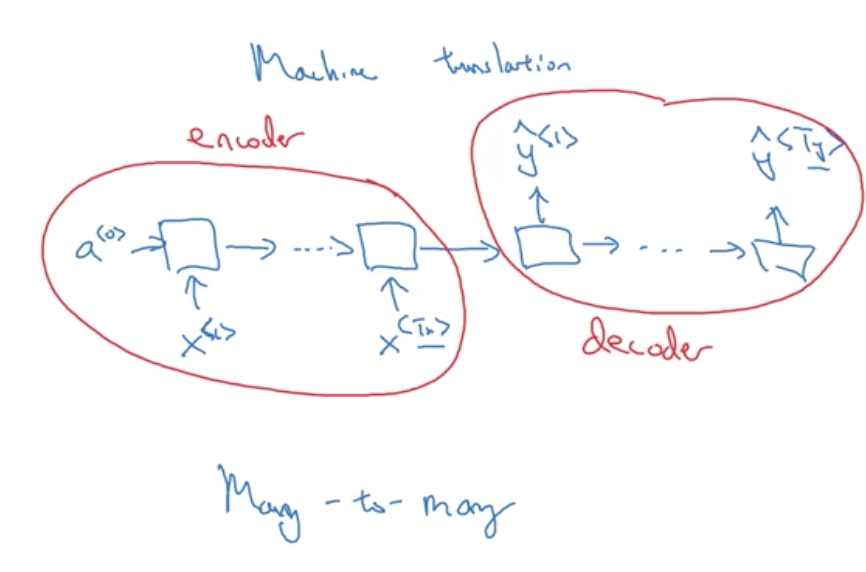
(4)编码和解码
4 语言模型和序列生成
4.1 什么是语言模型
案例:
假設我們要建構一個語音辨識系統 當你聽到以下句子: 「蘋果和梨子沙拉很好吃」
所以你聽到了甚麼 我是說「蘋果和一對沙拉很好吃」還是「蘋果和梨子沙拉很好吃」(注:
英文中一對(pair)和梨子(pear)同音)
而語音辨識系統挑出第二句的方法 是透過語言模型 來告訴我們這兩句子各自的機率為何 例如,
一個語言模型可能會說第一句的 機率是3.2乘以10的-13次方
第二句的機率是5.7乘以10的-10次方 有了這些機率, 第二句是更為可能的
因為和第一句相比10的指數多3 所以系統會挑出第二句語言模型做的事是給定特定句子 它能告訴你特定句子的機率為何 我說的機率是指, 如果你想拿起隨機一份報紙, 隨機打開一個電子郵件或一個網頁或 聽你的朋友說的下一件事 此特定句子, 比如說剛提到的蘋果和梨子沙拉 在這世界中被使用到機率為何 這是以下兩者的基礎要件: 剛提到的語音辨識系統 和機器翻譯系統 我們會期望它輸出最有可能出現的句子
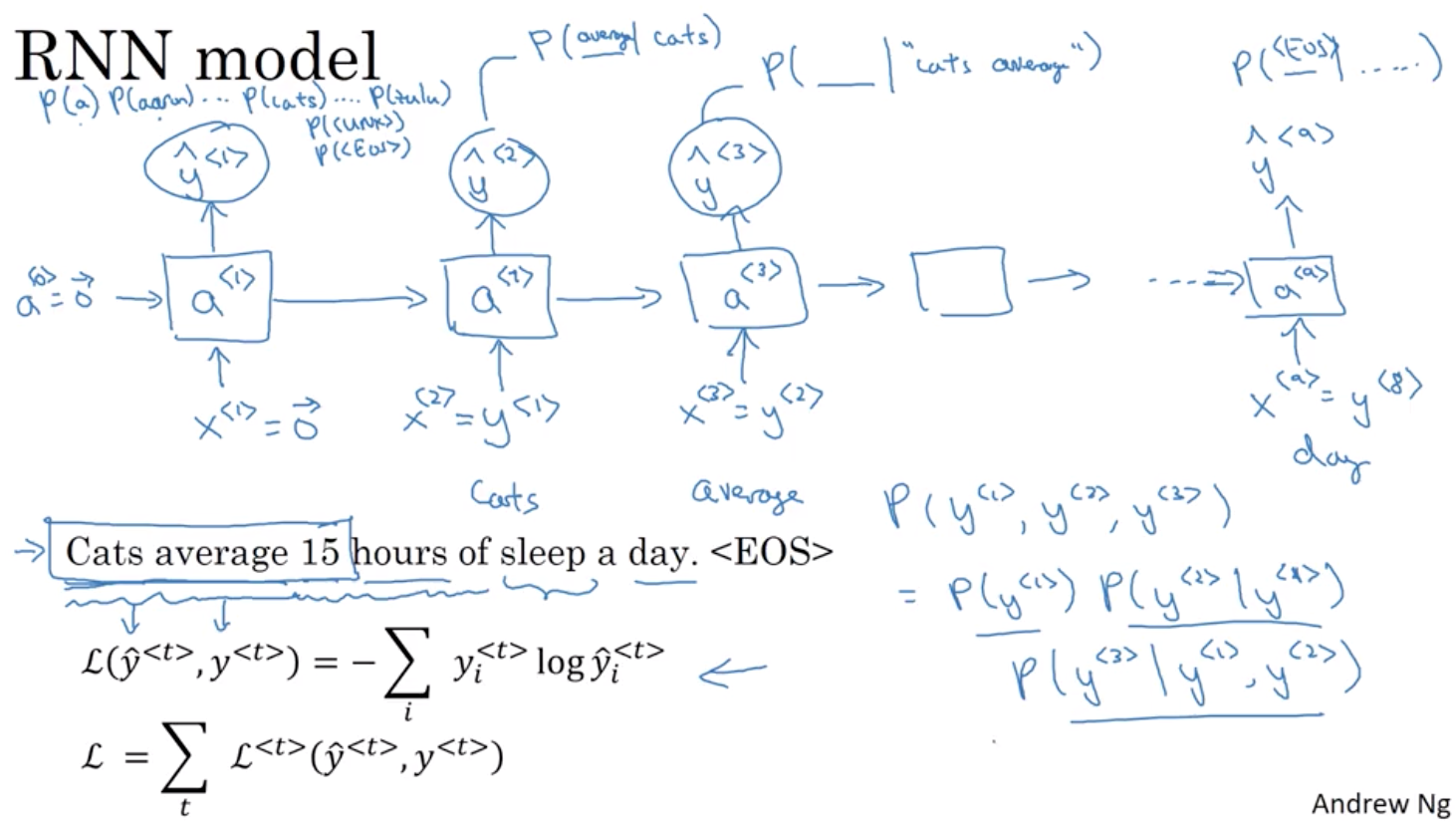
因此, 語言模型的基礎工作是輸入一個 我會將其寫成y^<1>, y^<2> 到 y^
的句子 語言模型做的是將句子表示為 y 而不是 x, 但語言模型做的事是預測 該特定字詞序列的機率

5 如何构建语言模型
- 首先我们需要一个大型的语料库(Corpus)
- 将每个单词字符化
- 2个特殊的单词:EOS( end of sentence 终止符)、UNknown(字典里没有收录的字词)
之所以将真实值作为输入值很好理解,如果我们一直传错误的值,将永远也无法得到字与字之间的关系。
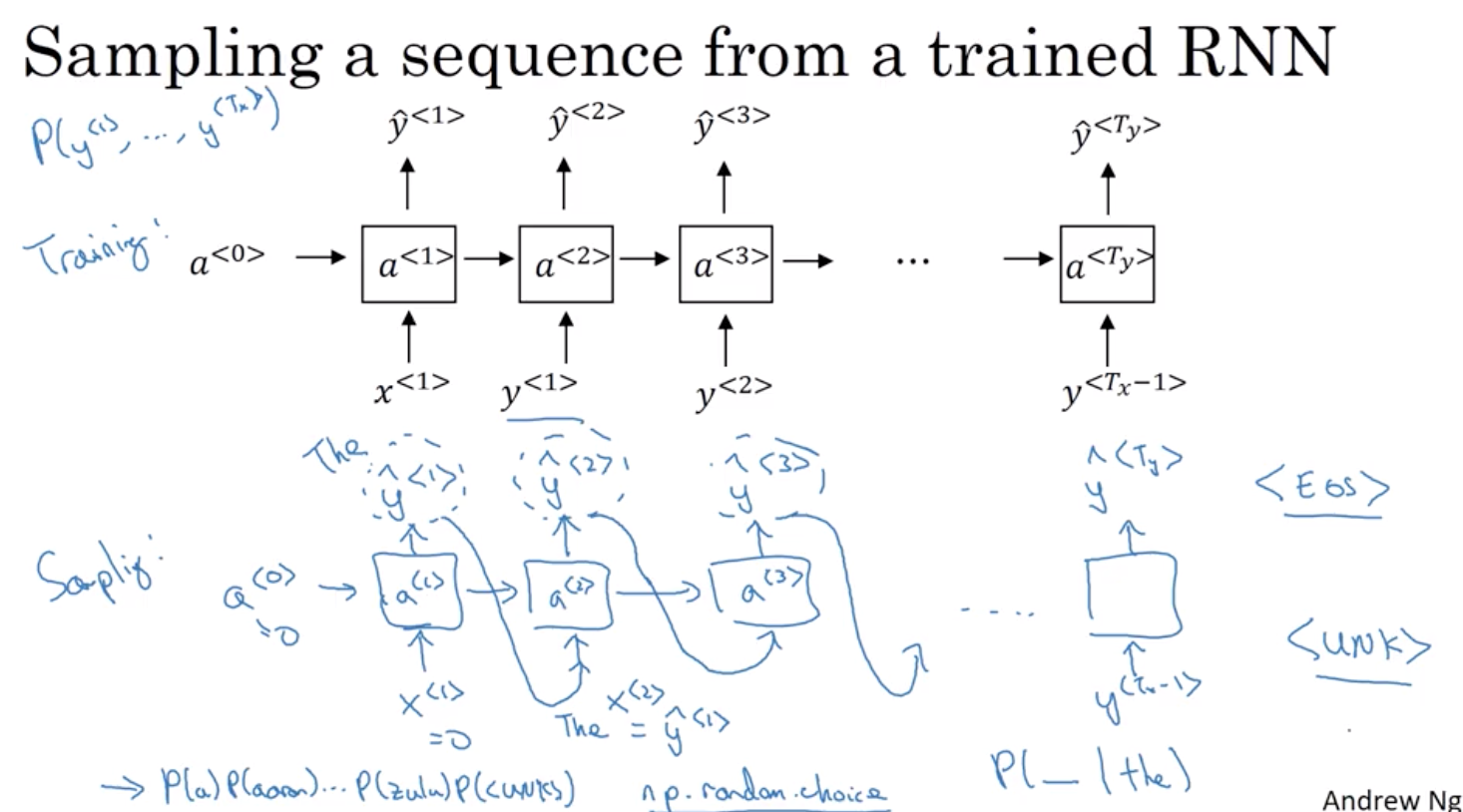
6 新序列的采样

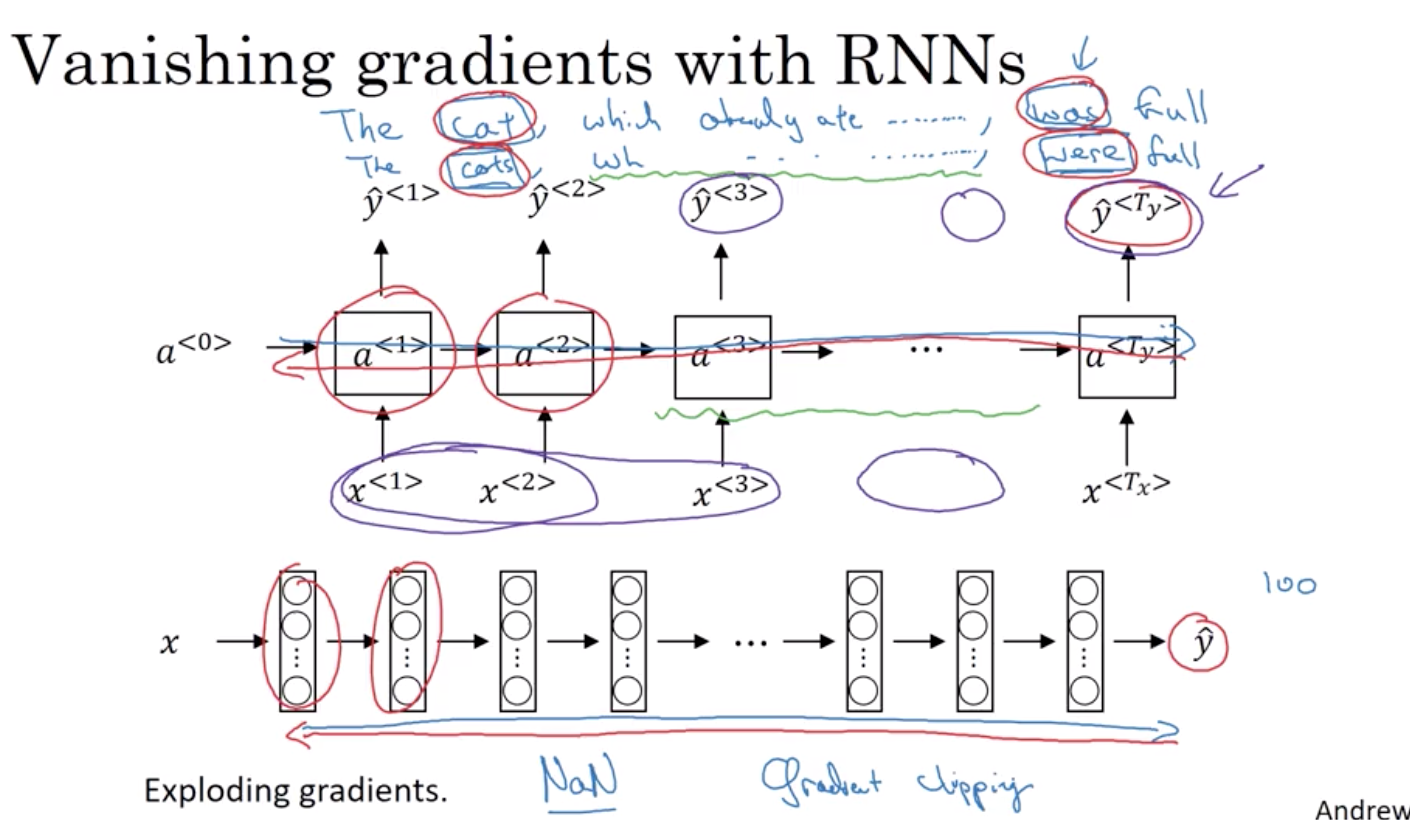
7 如何解决梯度消失的问题
7.1 梯度爆炸
你還記得我們也提到非常深層的神經網路 也有提到梯度爆炸的問題 當進行反向傳播時 梯度不僅可能呈現指數下降 當計算到越深層時, 也可能呈現指數上升 事實上, 當訓練RNN網路時, 儘管梯度消失是較為嚴重的問題 但梯度爆炸也是有可能發生 這可能使神經網路崩潰 因為指數項非常大的梯度可能會造成 參數也隨之變的非常大, 讓神經網路無法被使用 而梯度爆炸很容易被發現 因為你的參數可能會變成 NaN 或者是 顯示為非數字的情況 代表神經網路計算中出現數值溢位問題 如果你真的遇到了梯度爆炸 有可解決方法是運用梯度修剪(gradient clipping) 它代表的是 觀察你的梯度向量 如果它大於某個閾值 重新縮放梯度向量, 確保它不會太大
7.2 梯度消失
這是一個非常深的網路 假設有100層或更多, 你會從左至右做正向傳播 然後再做反向傳播 我們曾說過, 如果這是很深的網路 那從輸出 y 得到的梯度 會非常難以做反向傳播 並進而難以影響前面幾層的權重 難以影響這裡的計算
8. GRU(gated recurrent unit 门控循环单元)
8.1 门控单元的原理
(Gate Recurrent Unit) 一種修改 RNN 隱藏層的方式,使得它更能捕捉 長距離的連結, 對於梯度消失問題有很大幫助
对RNN的一个隐藏层可视化:
您或許需要記住,貓 (cat) 是單數 來確定您理解為什麼使用 “was” 而不使用 “were” 所以 “cat was full” 或者 “cats were full” 當我們從左到右讀這一段句子 GRU 單元將會有一個新的變數稱為 c 代表細胞 (cell) 記憶細胞 而記憶細胞的作用是提供一點點記憶來記住,舉例 貓 (cat) 是單數還是複數 所以當它進入這個句子更後面時 它還可以在工作時考慮到 句子的主題 是否是單數還是複數 所以在時間 t 時,記憶細胞會有一些值 c
gammaU、C、C候选值,可以是向量,gammaU不一定全是0/1,只是逐元素告訴 GRU 單元 哪一些位置,只是告訴您哪些 記憶細胞的維度需要在每個時間步驟中更新 所以您可以選擇保持一些位置不變 當更新其他位置時 舉個例子,或許您可以選擇一個位置來記住 貓是單數還是複數,或許使用 其他一些位置來記住您談的是有關於食物


8.2 门控单元的优点
因為 gamma 可以相當接近 0 可能是 0.000001 甚至更小 它不太會有梯度消失的問題 因為您說 gamma 相當接近 0 這個基本上會讓 c
等於 c 而 c 的值會相當程度的保留 即使經過了很多很多時間步驟 所以這個可以明顯地幫助解決梯度消失問題 而讓神經網路可以使用甚至更長的距離的依賴性
8.3 完整版GRU

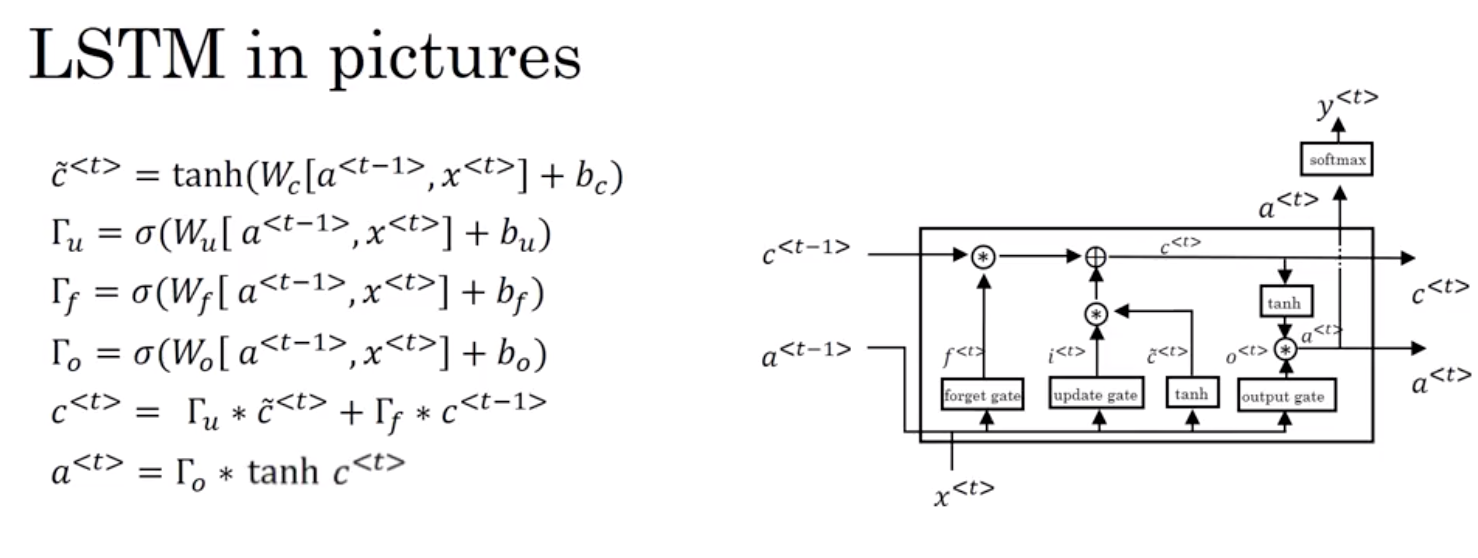
9. LSTM 长短期记忆单元
LSTM 的一個新特性是 並非只用一個更新門閘來控制記憶過程 如這裡的兩個項 我們是用兩個不同來源的項 我們不再只用 Γᵤ 和 (1-Γᵤ) 而是在這裡用 Γᵤ 然後用遺忘門閘 Γf 那這個 Γf 門閘 用到了 sigmoid S型函數
其它和你之前看到的差不多 這裡是 x並加上 bf 然後我們會有一個新的輸出門閘 一樣是sigmoid S型函數, 用到 Wₒ 最後加上 bₒ 然後, 記憶細胞的更新值 c 等於 Γᵤ 這個 * 表示矩陣中逐元素的乘積 這是個向量間逐元素乘積 再加上, 取代 (1-Γᵤ) 用的是另一項遺忘門閘 Γf 乘以 c 這樣給了記憶細胞選擇權 去決定使用多少舊數值 c 並直接加上新的值 c~ 所以這裡是使用兩個分開的項, 更新門閘和遺忘門閘 這些代表更新門閘, 遺忘門閘, 還有輸出門閘 最後, 取代 GRU 中的 a =c a 等於輸出門閘和 c 去做逐元素乘積 那這就是 LSTM 的主要方程式 它用了三個門閘, 而並非兩個 並把三個門閘用到了不同的地方

10. 双向RNN模型
「雙向 RNN 模型」 它讓你在序列的某個時間點上 可以同時獲得過去或未來的資訊
這就是雙向 RNN 的運作 而這些 RNN 單元不僅可是標準的 RNN 單元 也可以是 GRU 或是 LSTM 單元 事實上, 大多是自然語言處理問題 特別是有大量文本的問題 有 LSTM 單元的雙向 RNN 是很常被使用的 所以, 如果你遇到了 NLP 問題, 而且句子都是完整的 並想嘗試標記這些句子 一個有 LSTM 單元的雙向 RNN 有前向和反向的計算, 應該會是你的首選

11. 深度RNN
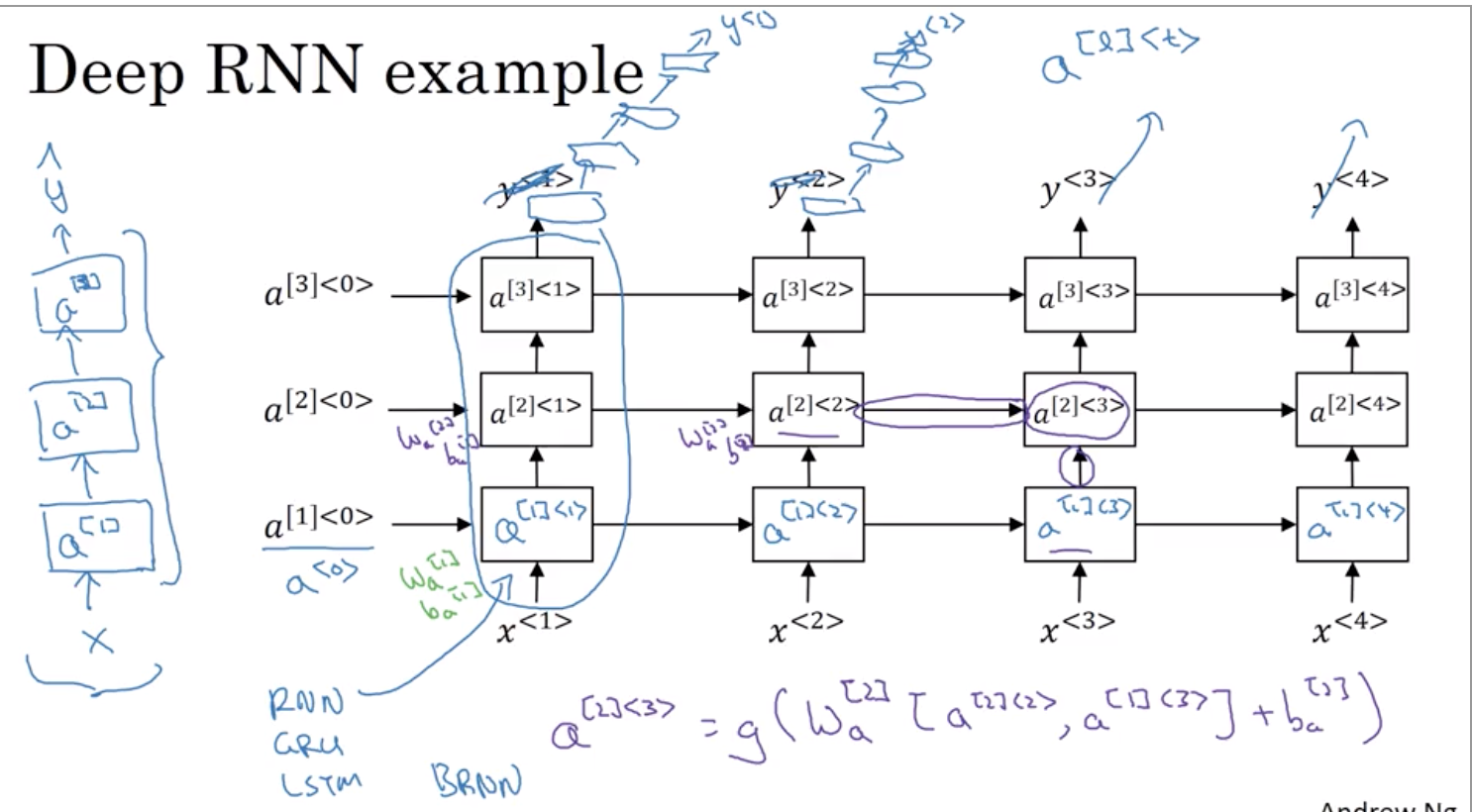
在上图所示框架基础上
,可以改进的地方(1): 在RNN之后,然後用一些深度層但不用水平連結 使用深度網路來最後預估 y<1> 您可以用相同的深度網路來預估 y<2> 所以這種網路架構比較常見 您有三個遞迴單元以時間相連 連結一個網路 之後連結一個網路 就像 y<3> 跟 y<4> 一樣 這裡有深度網路,但這些並沒有水平連結 所以這是一種比較常見的架構
改进(2):這些區塊不只一定是標準的 RNN 簡單的 RNN 模型 它們也可以是 GRU 區塊,或是 LSTM 區塊
改进(3):您也可以在雙向 RNN 上建立深度版本